![]()
©2003 - 2015 openEHR基金会

修订记录
本文件所报告的工作由下列组织提供资金:
特别感谢CHIME负责人David Ingram教授,他提供了自GEHR(1992年)时代以来的愿景和合作的工作环境。
[TOC]
本文档根据模型概述,关键全局语义,部署和集成架构,与已发布标准的关系以及最终构建实施技术规范(ITS)的方法,概述了openEHR架构。在每个信息,原型和服务模型特定的语义在相关模型中描述。
目标受众包括:
本文档是openEHR的关键技术概述,应在所有其他技术文档之前阅读。
此规范处于STABLE状态。本文档的开发版本可以在http://www.openehr.org/releases/BASE/latest/architecture_overview.html找到。
已知的遗漏或问题在文本中用“待定”段落表示,如下:
TBD :(例如待定段落)
鼓励用户对这些段落以及主要内容发表评论和/或建议。应在技术邮件列表或规范问题跟踪上提供反馈。
本文档提供了openEHR架构的概述。它开始于规范项目的描述,然后概述参考模型结构和包。然后描述包括安全性,原型,标识,版本和路径的关键全局语义。指出了与已发布标准的关系,最后概述了构建实施技术规范(ITS)的方法。
图1说明了openEHR规范项目。该项目负责开发openEHR健康计算平台所基于的规范。计算平台的各部分和规范之间的关系在图上指示。项目可交付成果包括需求,抽象规范,实施技术规范(ITS),可计算表达式和一致性标准。
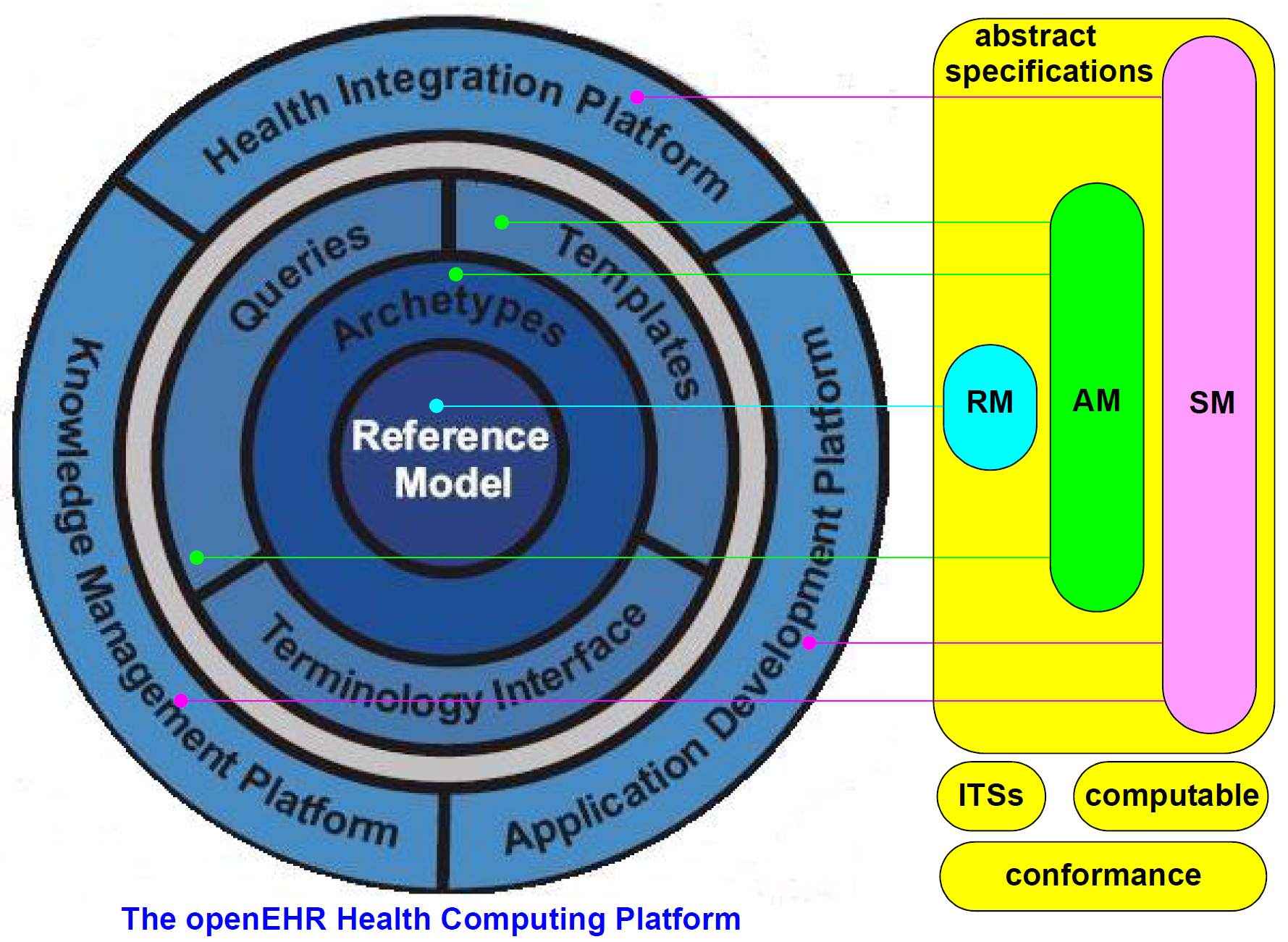
抽象规范包括参考模型(RM),服务模型(SM)和原型模型(AM)。前两个分别对应于ISO RM / ODP信息和计算观点。后者形成了信息模型和知识资源之间的桥梁。
openEHR发布的抽象规范使用UML符号和正式文本类规范来定义。这些模型构成所有openEHR语义的主要参考。这些抽象规范的表示风格故意旨在清楚和语义上接近正在传达的想法。因此,规范不遵循特定编程语言,模式语言或其他形式主义的习语或限制。
规范还提供了面向工具的可计算UML格式,以便能够开发软件和系统。用于所有实际目的的可计算表达式可以被假设为已公布的抽象规范的无损表示。
另一方面,实现技术规范对应于各种编程和模式语言中的抽象规范的表达,其中每个表示来自规范模型的不完全的并且通常是部分的变换。有许多实现技术,从编程语言,诸如XML的串行形式,到数据库和分布式对象接口。每一个都有自己的限制和优势。在给定实现技术中实现任何openEHR抽象模型的方法是首先为特定技术定义ITS,然后使用它来将抽象模型正式映射到该技术中的表达式中。
本节简要概述了openEHR架构的基本要求。 openEHR架构体现了来自世界各地的许多项目和标准的15年研究。它是基于多年来捕获的需求而设计的。
因为该架构是高度通用的,并且特别是由于原型驱动,它满足在“临床EHR”的原始概念之外的许多要求。例如,相同的参考架构可以用于兽医健康或甚至“照顾”公共基础设施或列出的建筑物。这是因为参考模型只体现与“关于护理主题的服务和行政事件”有关的概念;在原型和模板中,定义了护理事件和护理主题的细节。在另一个方面,虽然openEHR EHR的要求之一是“以患者为中心,纵向,共享护理EHR”,但不限于此,并且可以在纯粹的情景,专家情况下使用,例如作为放射科的记录系统。对各种口味的“保健记录”的要求可以根据受试者的两个维度,范围和种类分类,如下所示。
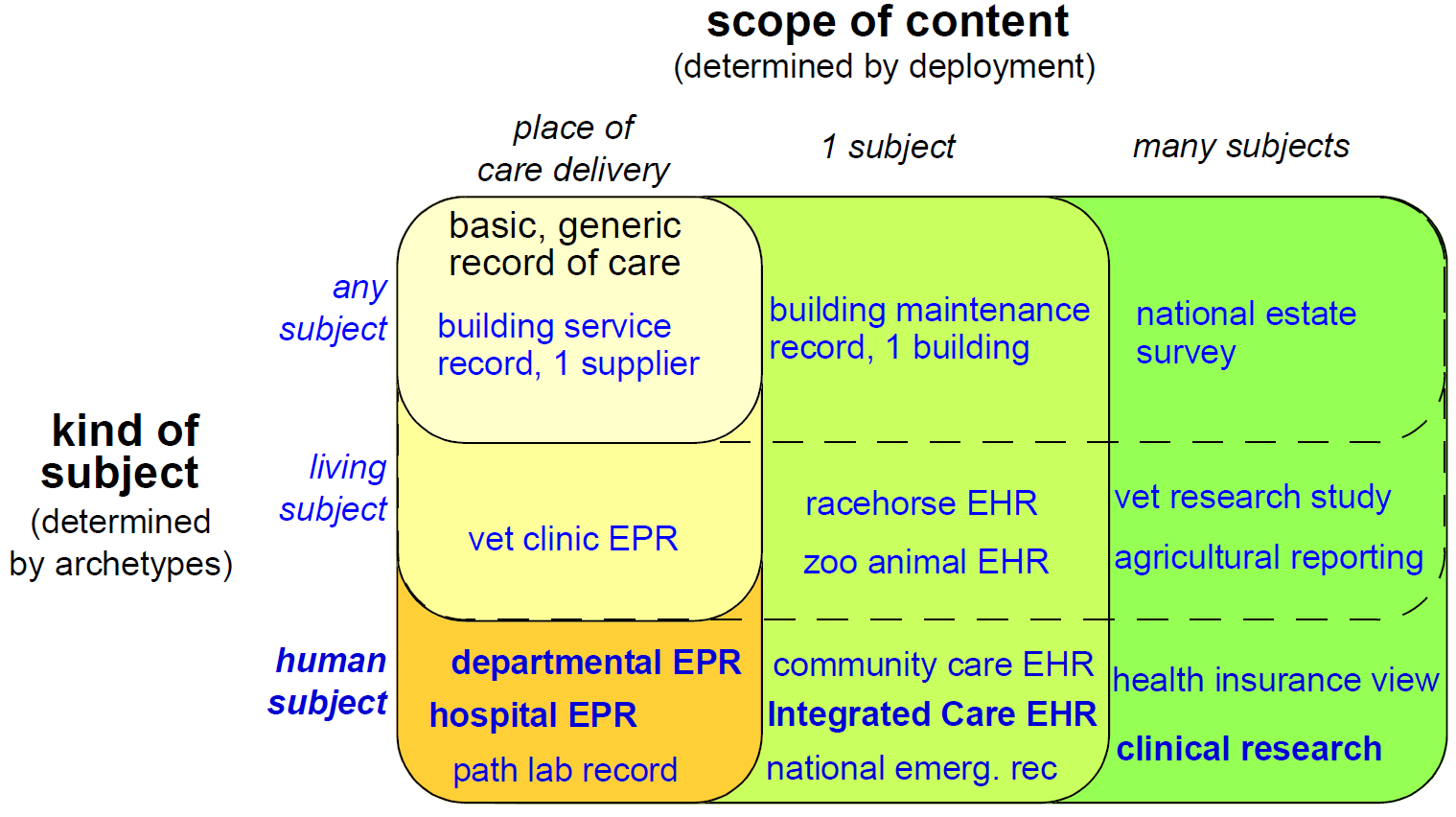
在该图中,每个气泡表示一组要求,作为其中包含的气泡的所有要求的超集。对于本地部署中的任何类型的主题的护理的通用记录的要求由左上方的气泡表示。随后添加对应于活体和然后人类对象的需求由在图的左侧的气泡表示。左侧最大泡沫所代表的要求对应于“人类护理的本地健康记录”,例如放射学记录,医院EPR等。由越过图表的较宽气泡表示的附加的要求集合对应于首先将护理记录的内容的范围扩展到整个受试者(导致以患者为中心的纵向健康记录),然后到受试者的群体或群体,如在人口健康和研究中所做的那样。从(人类)医疗保健的角度来看,重要的需求组一直延伸到图表的底行。
沿着图,对应于护理主体(从“任何”到“人”)的增加的特异性的要求大多在openEHR中通过使用原型来实现。跨越图,对应于增加记录内容(从情节到人口)的范围的要求主要表现在不同的部署中,通常从独立到共享的可互操作形式。今天EHR的主要愿望之一是许多卫生当局今天所寻求的“综合护理记录”(参见ISO_20514关于ICEHR的定义),它为综合共享护理提供了一个信息框架。
作为openEHR所采用的方法的结果,构建为满足集成共享保健记录的要求的组件和应用也可以被部署为(例如)情景放射学记录系统。
在GEHR演进期间开发的打开EWR的一些关键要求在以下部分中列出,对应于openEHR满足的要求结构的一些主要需求组。
openEHR要求包括以下内容,对应于基本的通用护理记录:
openEHR中解决的以下要求对应于本地健康记录或EPR:
openEHR中解决的以下要求对应于集成共享护理EHR:
从更具体的临床护理角度(而不是记录保存的角度),在openEHR的开发过程中已经确定了以下要求:
综合护理EHR拥有巨大的希望:为已经单独和孤立的环境,广泛提供的计算机化的好处。这些可以总结如下:
减少由于药物错误(如相互作用,重复或不适当的治疗)引起的不良事件以及与其相关的流量成本;
关于EHR要求的一个全面的声明包括上述许多是ISO技术报告18308 [ISO18308],为其创建了openEHR配置文件[openehr18308]。上面概述的要求在openEHR EHR信息模型文档中有更详细的描述。
3.3. 部署环境
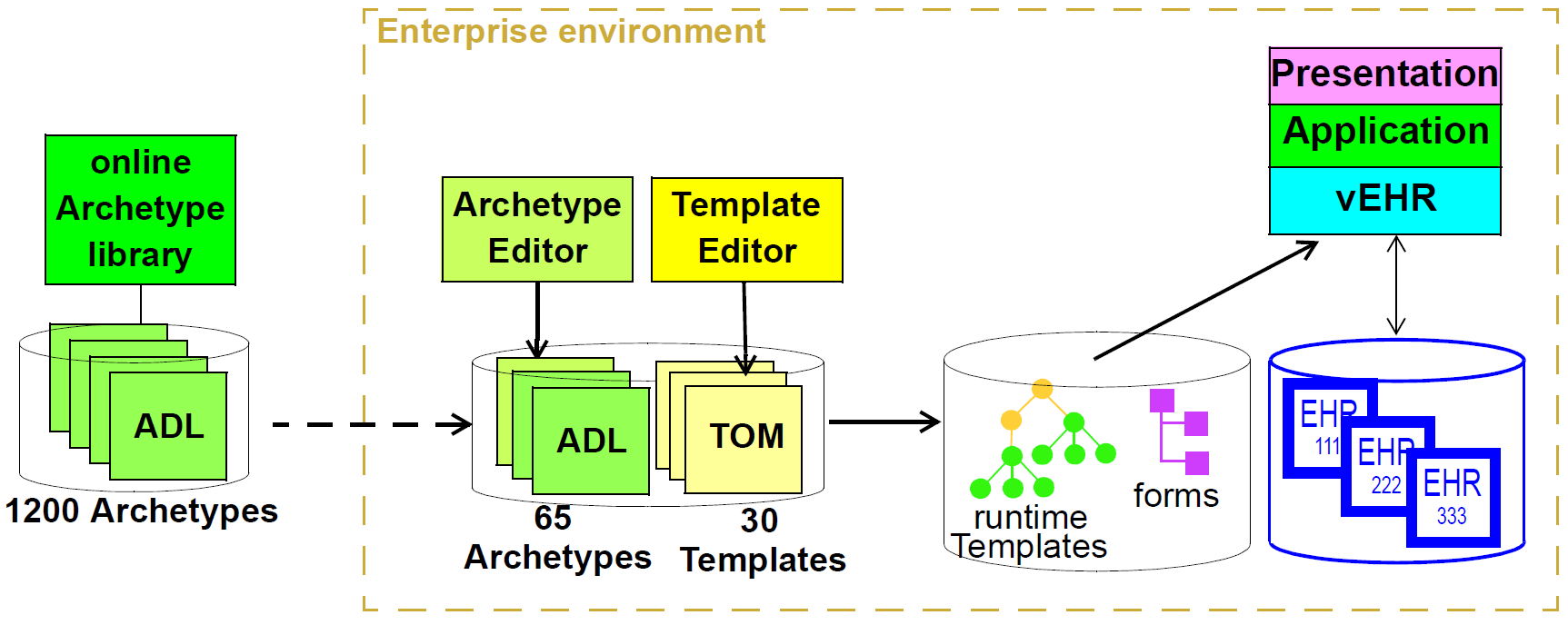
最终,任何软件和信息架构仅在部署时提供实用程序。 openEHR的架构旨在支持多种类型的系统的构建。其中最重要的,综合共享医疗健康记录如下图所示。
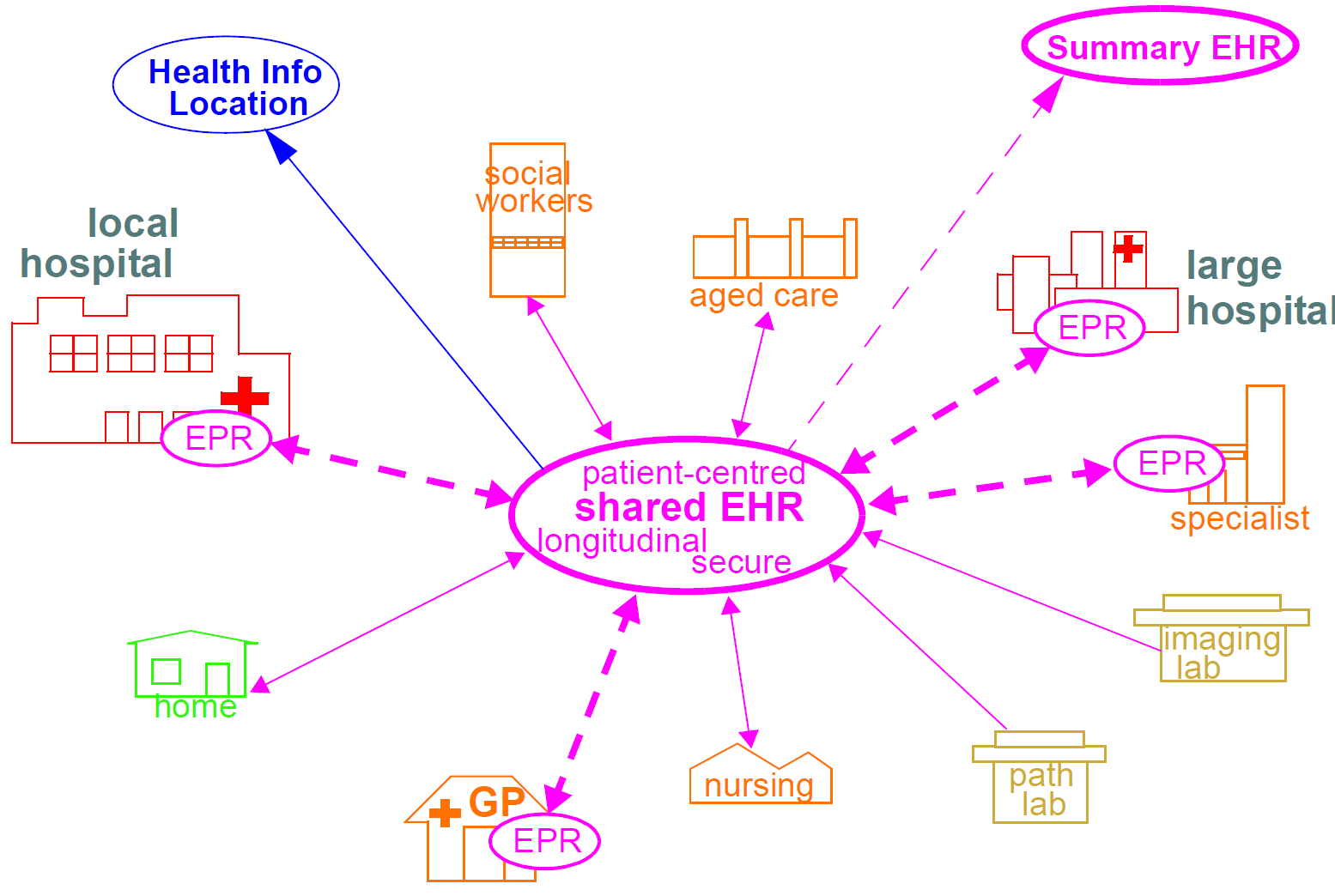
在这种形式下,openEHR服务被添加到现有的IT基础设施中,为在其社区环境中由任何数量的健康提供者看到的患者提供共享的,安全的健康记录。支持openEHR的系统也可用于在提供商位置提供EMR / EPR功能。总的来说,使用openEHR可以实现一些重要的系统类别,包括:
openEHR方法对信息,服务和领域知识进行建模是基于一些设计原则,如下所述。这些原理的应用导致openEHR架构的模型的分离,并因此导致高水平的组件化。这导致更好的可维护性,可扩展性和灵活的部署。
在任何模型系统中最基本的区别是本体论,即在现实世界的描述的抽象层次。所有模型都携带某种语义内容,但并非所有语义都是相同的,甚至是相同的类别。例如,SNOMED_CT术语的一些部分描述了细菌感染的类型,身体中的部位和症状。信息模型可以指定逻辑类型数量。内容模型可以定义医生在产前检查中收集的信息的模型。这些类型的“信息”在质量上是不同的,并且需要在整个模型生态系统内单独开发和维护。下图说明了这些区别,并指出了哪些部分直接构建到软件和数据库中。
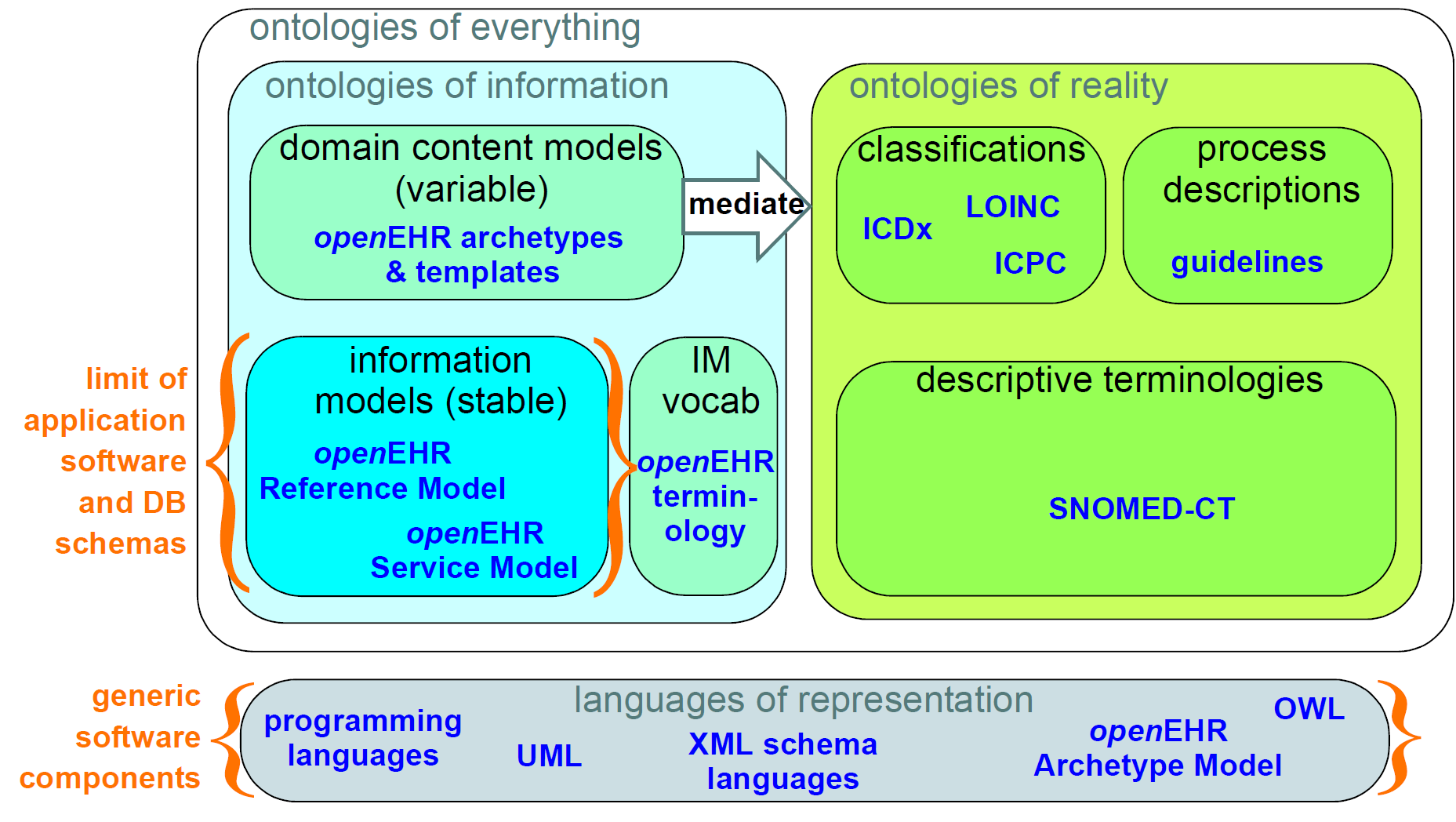
该图示出了“信息本体”即信息内容的模型和“现实本体”即真实现象的描述和分类之间的主要分离。这两个类别必须分开,因为作者的类型,表示和目的是完全不同的。在健康信息学中,由于术语和分类的发展,这种分离已经存在。
在信息模型和域内容模型之间示出了信息侧内的次级本体分离。前一类别对应于跨域不变的语义(例如,基本数据类型,如编码项,数据结构,如列表,标识符),而后者对应于可变域级内容描述 - 信息结构的描述,例如“微生物学结果”而不是真实世界中的实际现象的描述(例如微生物的感染)。这种分离通常不是很好理解,在历史上,大量的域级语义已经硬连接到软件和数据库,导致相对不可维护的系统。
通过清楚地分离三个类别 - 信息模型,域内容模型和术语 - openEHR架构使每个人都有一个明确定义,有限的范围和清晰的接口。这限制了每个的相互依赖,导致更可维护和适应性更强的系统。
OpenEHR所基于的关键范例之一被称为“两级”建模,在Beale_2000中描述。在两级方法下,稳定的参考信息模型构成第一级建模,而原型和模板形式的临床内容的正式定义构成第二级。只有第一级(参考模型)在软件中实现,显着降低了部署的系统和数据对可变内容定义的依赖性。在软件中实现的模型世界的唯一其他部分是高度稳定的语言/表示模型(在图的底部显示本体景观)。因此,系统具有比单级系统小得多和更可维护的可能性。它们也固有地是自适应的,因为它们被构建为在将来开发时使用原型和模板。
原型和模板也是术语,分类和计算机化临床指南的明确的语义网关。过去的替代方案是尝试使系统功能完全与硬连线软件和术语的组合。这种方法是有缺陷的,因为术语不包含域内容的定义(例如“微生物学结果”),而是关于真实世界的事实(例如微生物的种类和人类感染的影响)。
在openEHR中使用原型会在信息和模型之间产生新的关系,如下图所示。
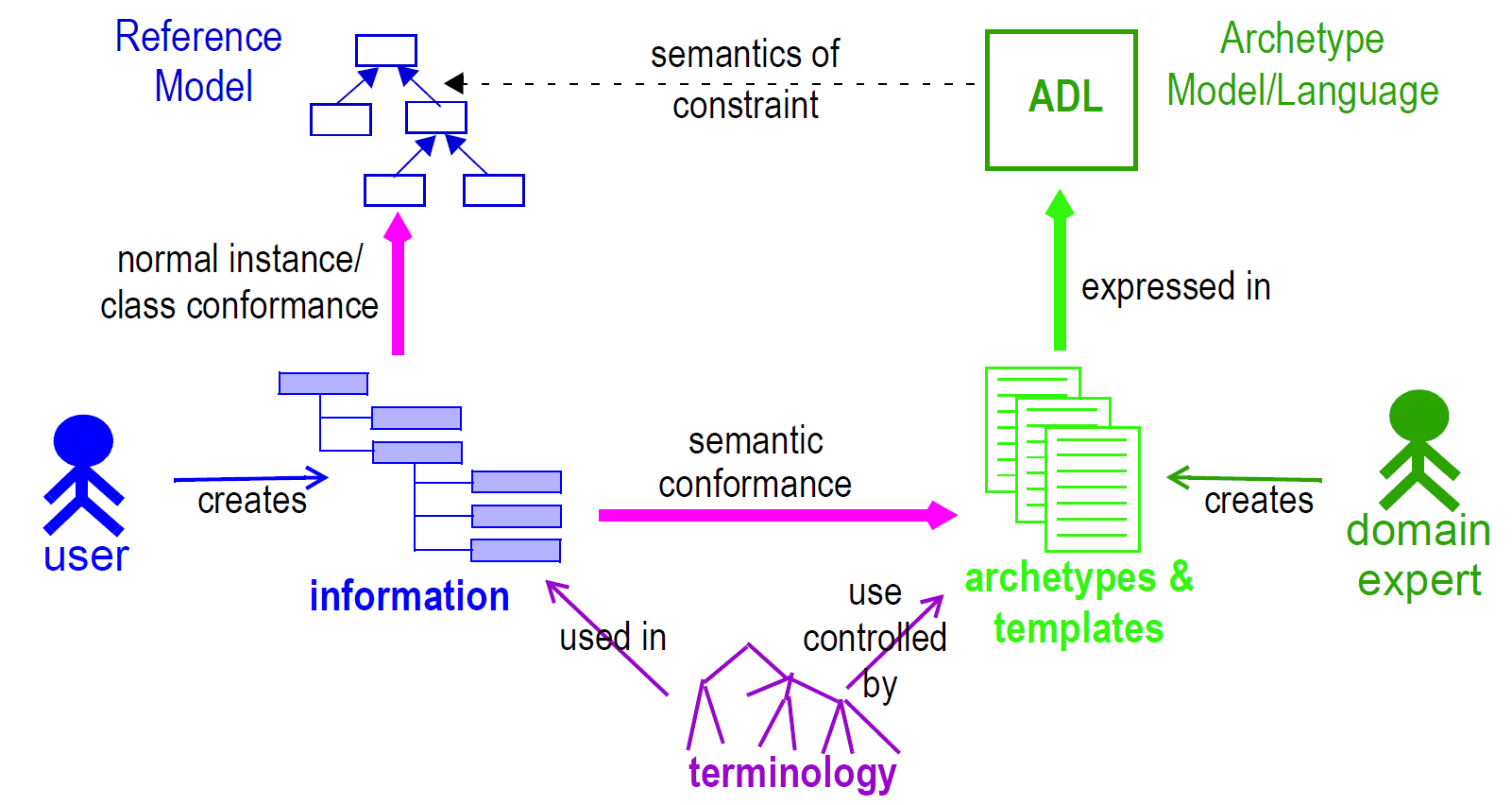
在这个图中,我们在正常信息系统(左下方所示)中知道的“数据”符合通常的对象模型(左上)。以“经典”方式设计的系统(即,所有领域语义在软件或数据库中的某处被编码)局限于这种架构。通过使用两级建模,运行时数据现在在语义上符合原型以及具体到参考模型。所有原型都以通用原型定义语言(ADL)表示。
有关原型和模板在openEHR中的工作原理的详细信息,请参见原型和模板一节。
两级建模显着改变了系统开发过程的动态。在通常的IT密集型流程中,通过与用户的特别讨论(通常通过众所周知的“用例”方法)收集需求,根据需求构建设计和模型,从设计实现实现,然后测试和部署并最终实现生命周期的维护部分。这通常的特征在于实施变化的持续高成本和/或系统能力与任何时刻的需求之间的差距日益扩大。该方法还受制于与系统用户的特别对话几乎总是未能揭示基本内容和工作流的事实。在两级范式下,系统的核心部分基于引用和原型模型(包括用于存储,查询,缓存等的通用逻辑),这两种模型都非常稳定,而域语义大多数委托给域工作建筑原型(可重复使用),模板(本地使用)和术语(一般使用)的专家。该过程如下图所示。在这个过程中,IT开发人员专注于通用组件,如数据管理和互操作性,而领域专家组在软件开发过程外工作,生成系统在运行时使用的定义。
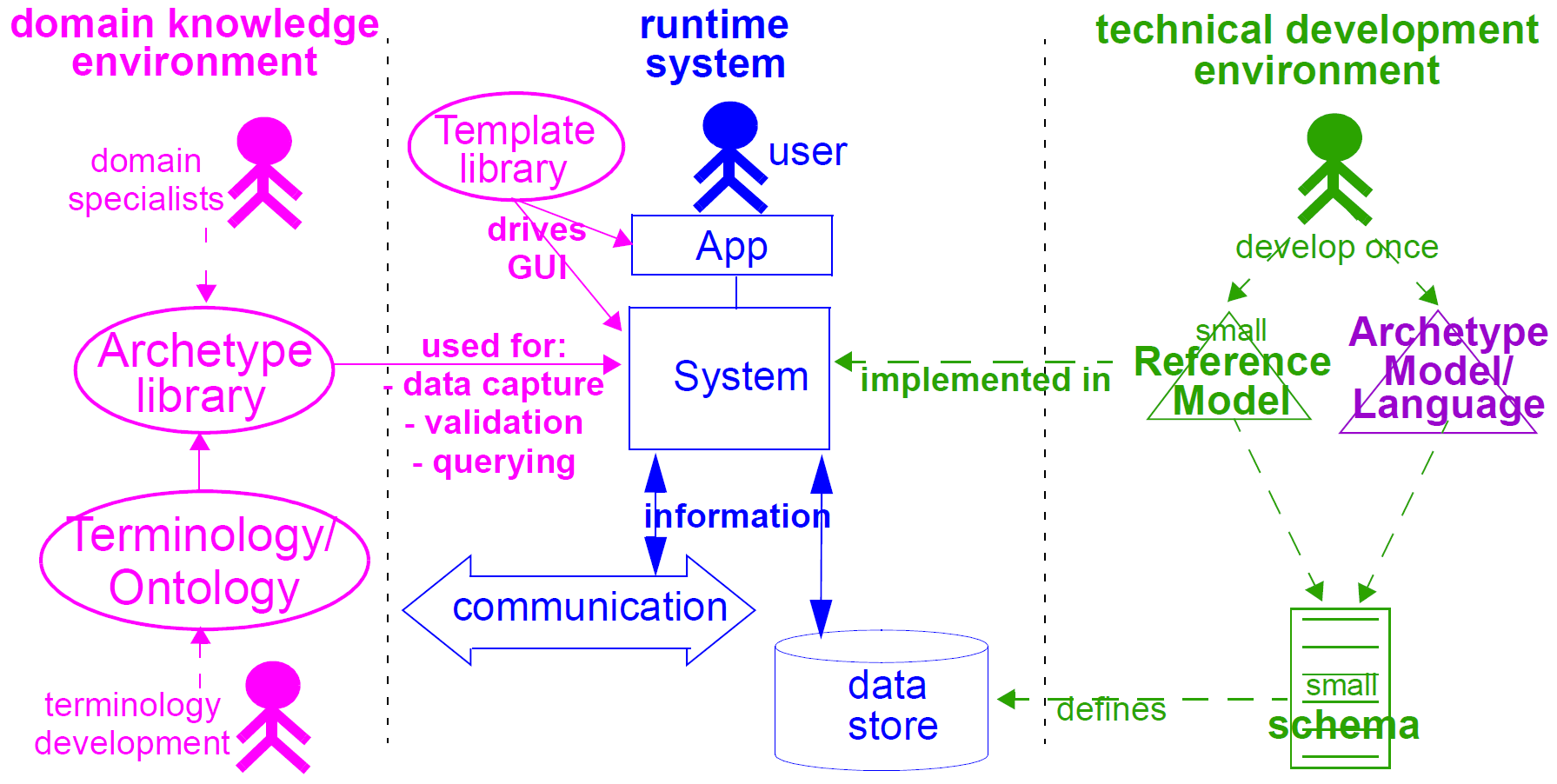
显然,应用程序不能总是完全通用的(虽然许多数据捕获和查看应用程序);决策支持,管理,调度和许多其他应用程序仍然需要定制工程。然而,所有这样的应用现在可以依靠原型和模板化的计算平台。这种方法的一个关键结果是,原型现在构成领域语义的技术独立的单源表达式,用于驱动数据库模式,软件逻辑,GUI屏幕定义,消息模式和语义的所有其他技术表达式。
openEHR中使用的第二个关键设计范例是在计算环境中分离职责。复杂域只有在功能首先被划分成广泛的感兴趣区域,即进入“系统系统”[6]时才可处理。这个原理在计算机科学中已经在“低耦合”,“封装”和“组件化”的概念中被理解,并且已经产生了非常成功的框架和标准,包括OMG的CORBA规范和面向对象的explosion语言,类库和框架。每个功能区域形成一组正式描述该区域的模型的焦点,这些模型通常对应于不同的信息系统或服务。
下面示出了包含许多服务的概念健康信息环境,每个服务由气泡表示。典型的连接由线表示,更接近中心的气泡对应于更接近临床护理递送的核心需要的服务,例如EHR,术语,人口统计/识别和医学参考数据。在图中所示的服务中,openEHR目前仅提供更为中心的规范的规范,包括EHR和人口统计。
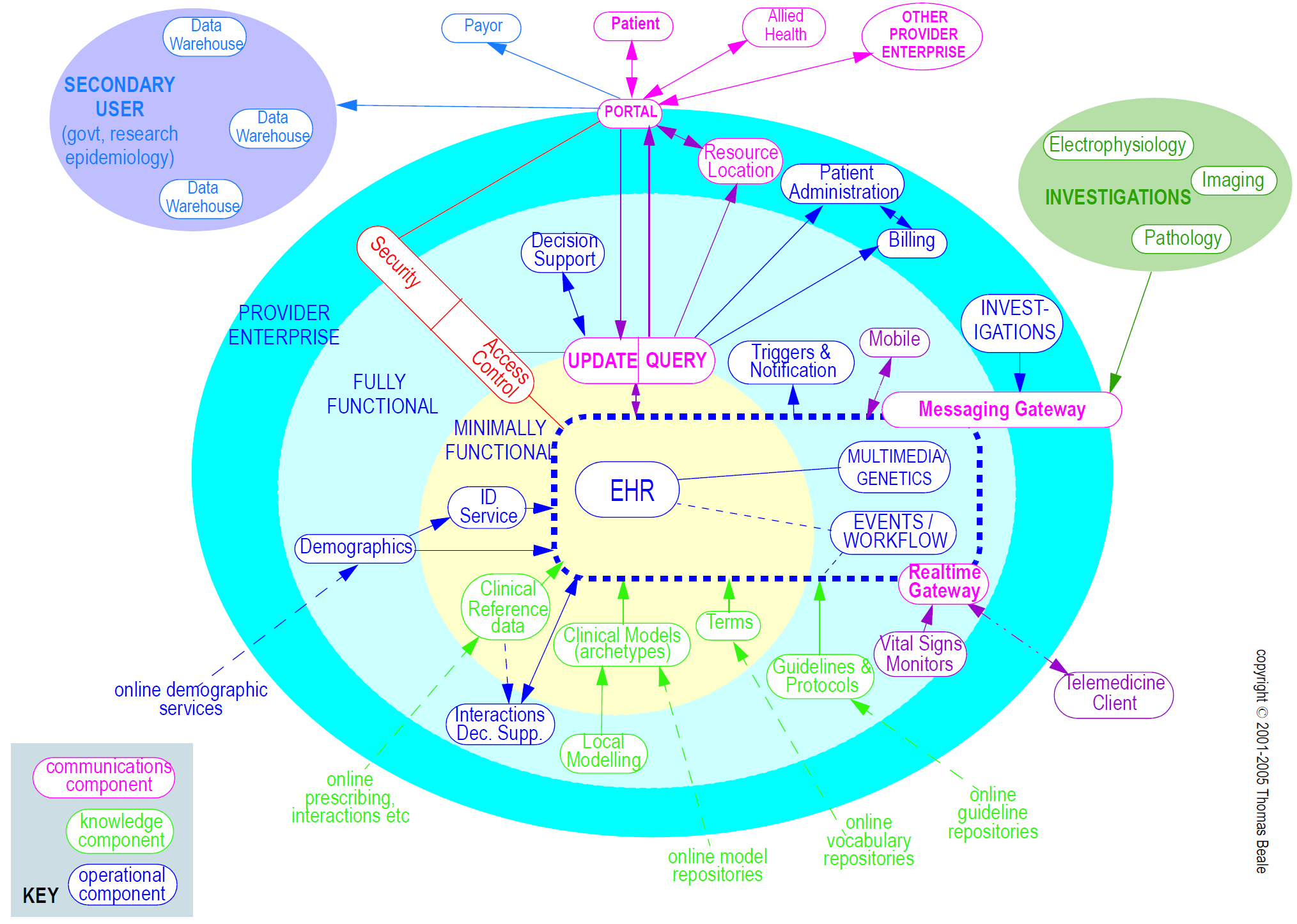
由于对于许多服务的某些方面,诸如术语,图像格式,消息,EHR提取,基于服务的互操作以及用于诸如日期/时间格式和字符串编码之类的细节的许多标准,存在标准,openEHR规范经常充当一个整合现有标准的机制。
openEHR中使用的第三种计算范式是责任分离的自然结果,即分离观点。当责任在不同组成部分之间分开时,有必要定义a)每个进程的信息,以及b)它们将如何通信。模型的这两个方面构成了ISO RM / ODP模型的两个中心“观点”[4],在下面以粗体标出:
企业: 涉及业务活动,即指定系统的目的,范围和政策。
信息: 涉及需要在系统中存储和处理的信息的语义。
计算: 涉及作为在接口处交互的一组对象的系统的描述 - 实现系统分发。
工程: 关注支持系统分布的机制。
技术: 涉及构成分布式系统的组件的细节。
openEHR规范相应地包括信息视点 - openEHR参考模型 - 和计算视点 - openEHR服务模型。工程视点对应于openEHR的实现技术规范(ITS)模型(参见实现技术规范),而技术视点对应于实际部署中使用的技术和组件。划分为视点的重要方面是在每个视点的模型规范之间通常不存在1:1关系。例如,在企业观点中可能存在“健康授权”(CEN ENV13940 Continuity of Care概念)的概念。在信息视点上,这可能已经成为包含许多类的模型。在计算视点中,在信息视点中定义的信息结构可能在多个服务中重现,并且可能有或可能没有“健康任务”服务。计算视点中定义的服务的粒度最强地对应于企业或区域中的功能划分,而信息视点中的组件的粒度对应于问题空间中的精神概念的粒度,后者几乎总是更多细粒度。
下图说明了openEHR形式规范的包结构。定义了三个主要软件包:RM,AM和SM。定义详细模型的所有包都出现在这些外部包之一中,这也可以被认为是命名空间。它们在org.openehr命名空间中概念性地定义,可以在UML中表示为进一步的包。在一些实现技术(例如Java)中,org.openehr命名空间实际上可以在程序文本内使用。
openEHR的重要设计目标之一是为科学和健康计算提供一致,一致和可重复使用的类型系统。 因此,RM(最底层)的“核心”提供标识符,数据类型,数据结构和各种常见的设计模式,其可以在RM的上层中,以及同样在AM和SM包中无处不在地重新使用。 下图说明了关键包之间的关系。 依赖性只存在于较高的包到较低的包。
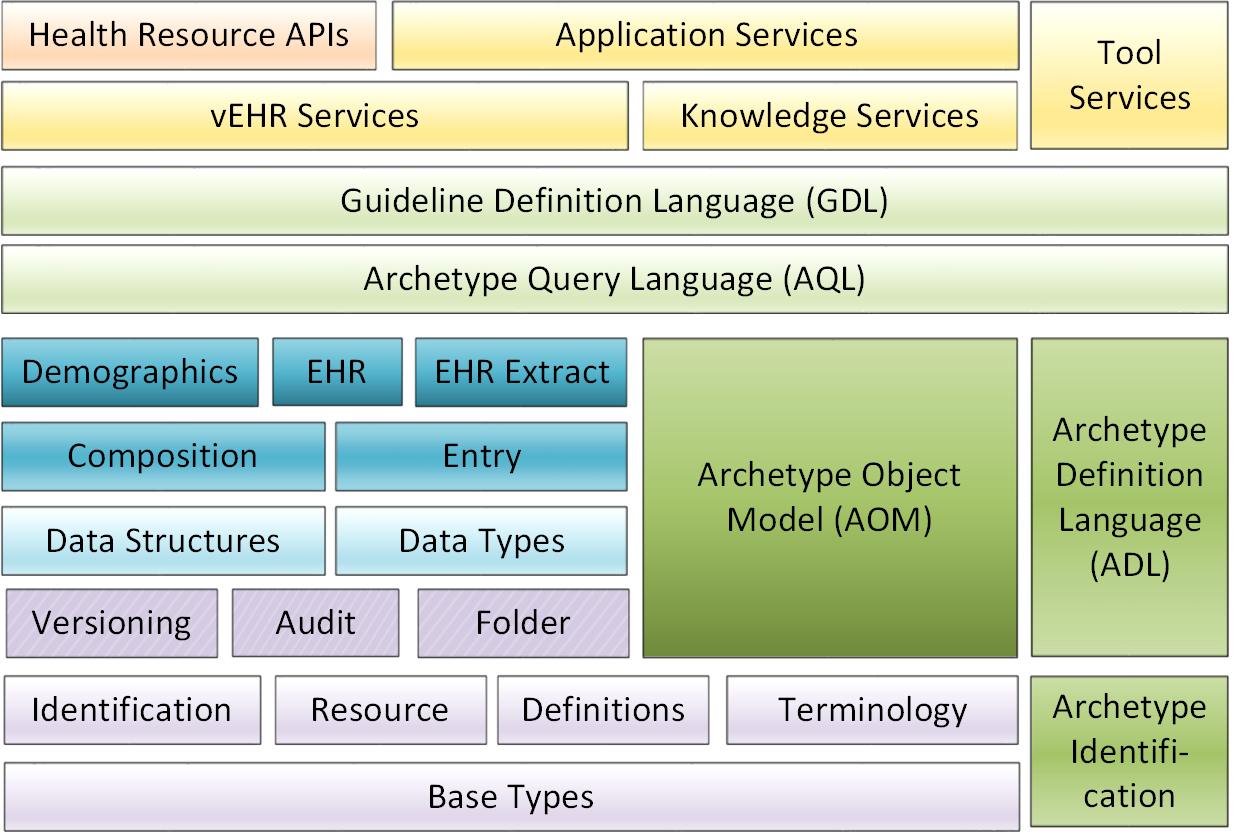
每个包定义了用于定义类的本地上下文。 下图说明了RM包结构。 显示了“领域”,“模式”和“核心”的非正式划分。 后一组中的包是通用的,并且由所有openEHR模型在所有外部包中使用。 它们一起提供识别,获取知识资源,数据类型和结构,版本化语义以及对原型设计的支持。 前组中的包定义了企业级健康信息类型的语义,包括EHR和人口统计。

org.openehr.rm包结构中的每个外包都对应一个openEHR规范文档(EHR和组合包除外,这两个包都在EHR参考模型文档中描述),记录“信息模型”(IM)。包结构通常将被复制在所有ITS表达式中,例如。 XML模式,Java,C#和Eiffel等编程语言,以及WSDL,IDL和.Net等互操作性定义。
以下小节提供了RM软件包的简要概述。
该包描述了所有其他包所需的最基本的概念,包括定义,标识,术语和测量包。这些包中定义的语义允许所有其他模型使用标识符并访问知识服务,如术语和其他参考数据。
在外部类型系统中描述openEHR假定的基本类型的特殊软件包assumetypes包含在支持包中,尽管它可能根据UML和其他建模工具的使用而移动。该软件包提供了将openEHR模型集成到实现技术类型系统中的指南。映射如String.isempty和一个例程empty()在一个编程库。 数据类型信息模型
一组明确定义的数据类型是所有其他模型的基础,并提供了各种健康信息所需的一些一般和临床特定类型。在数据类型参考模型中定义了以下类别的数据类型。
Basic types:布尔,状态变量。 Text:纯文本,编码文本,段落。 Quantities:任何有序类型,包括序数值(用于表示符号排序值,如“+”,“++”,“+++”),带有值和单位的测量数量等;包括日期/时间 - 日期,时间,日期时间类型和部分日期/时间类型。 Encapsulate data:多媒体,可解析内容。 TIME_specification:类型,用于指定未来的时间,主要用于药物订单,例如。 “饭前一天3次”。 Uri:唯一资源标识符。
在大多数openEHR信息模型中,通用数据结构用于表示其特定结构将由原型定义的内容。通用结构如下。
Single: 单个项目,用于包含任何单个值,如高度或重量。 List: 命名项目的线性列表,如许多病理测试结果。 Table: 表格数据,包括带有命名和有序列的无限长和有限长度表,以及可能命名的行。 Tree: 树形数据,其在概念上可以是列表的列表或其他深层结构。 History: 时间序列结构,其中每个时间点可以是由上述结构类型之一描述的任何复杂性的整个数据结构。支持点和间隔样本。
在更高级别包中重复的几个概念在公共包中定义。例如,类LOCATABLE和ARCHETYPED提供了信息和原型模型之间的链接。类ATTESTATION和PARTICIPATION是通用域概念,提供了一种标准方式来记录临床专业人员和其他代理参与EHR,包括签名。
change_control包定义了变更管理和版本控制的正式模型,适用于需要能够提供其信息的先前状态的任何服务,特别是人口统计和EHR服务。 openEHR中版本控制的关键语义在Versioning部分中描述。
安全信息模型定义了EHR中信息的访问控制和隐私设置的语义。
EHR IM包括ehr和组合包,并定义关键概念EHR,COMPOSITION,SECTION和ENTRY的包含和上下文语义。这些类是EHR的主要粗粒度组分,并且直接对应于CEN EN13606:2005中相同名称的类别,并且相当接近HL7临床文件架构(CDA)版本中相同名称的“级别” 2.0。
EHR提取IM定义如何从来自EHR的组成,人口统计和访问控制信息构建EHR提取。支持多种提取变体,包括“full openEHR”,一种用于与CEN EN13606集成的简化形式,以及一个openEHR / openEHR同步提取。
集成模型定义类GENERIC_ENTRY,ENTRY的子类型,用于将自由形式的遗留或外部数据表示为树。此Entry类型有自己的原型,称为“集成原型”,可以与临床原型一起用作基于工具的数据集成系统的基础。有关更多详细信息,请参阅将openEHR与其他系统集成。
人口统计模型定义PARTY,ROLE的通用概念和相关详细信息,如联系人地址。原型模型定义了PARTY的约束语义,允许描述任何类型的人,组织,角色和角色关系的原型。这种方法提供了一种灵活的方式来包括OMG HDTF PIDS标准Corbamed_PIDS中允许的任意人口统计属性。
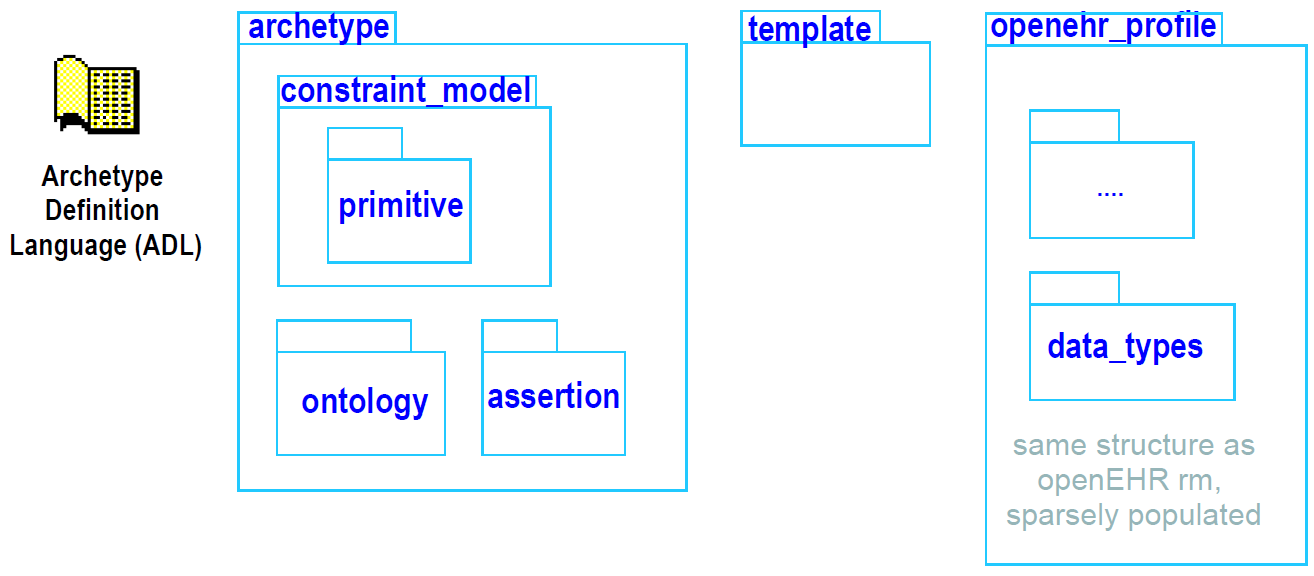
openEHR am包包含描述原型和模板的语义所需的模型,以及它们在openEHR中的使用。这些包括ADL,原型定义语言(以语法规范的形式表达),原型和模板包,定义原型和模板的面向对象的语义,以及openehr_profile包,其定义通用原型模型在原型包中定义,用于openEHR(和其他健康计算工作)。 am包的内部结构如下所示。
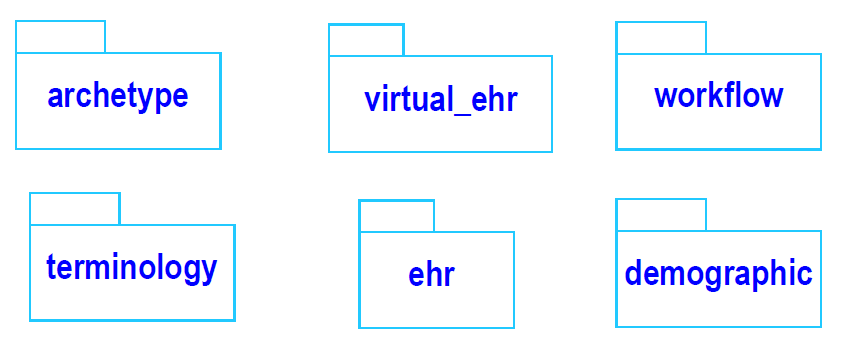
openEHR服务模型包括以EHR为中心的健康信息环境中的基本服务的定义。 如下图所示。 实际包括的服务集合无疑将随着时间的推移而发展,因此该图不应被视为明确的。
虚拟EHR API定义了EHR数据的细粒度接口,在Compositions级别和以下。它允许应用程序创建新的EHR信息,并请求现有EHR的部分并对其进行修改。此API支持细粒度原型介导的数据操作。对EHR的更改通过EHR服务提交。
EHR服务模型定义了电子健康记录服务的粗粒度接口。粒度级别是openEHR贡献和组合,即版本控制/变更集接口。
模型的一部分定义服务器端查询的语义,即导致大量数据被处理的查询,通常返回与特定标准匹配的患者的小的聚合答案,例如平均值或ID集合。
原型服务模型定义原型的在线存储库的接口,并且可以被设计用于人类浏览的GUI应用以及由诸如EHR的其他软件服务访问。
术语接口服务为所有其他服务提供了访问健康信息环境中可用的任何术语的手段,包括基本分类词汇(例如ICDx和ICPC)以及更先进的基于本体的术语。遵循系统上下文中的职责划分的概念,术语界面提取每个术语的不同底层架构,允许环境中的其他服务以标准方式访问术语。术语服务因此是通向环境中所有基于本体和基于术语的知识服务的门户,其中访问指南,药物数据和其他“参考数据”的服务使得能够在环境中进行推断和决策支持。
在信息术语中,基于openEHR的最小EHR系统由EHR库,原型仓库,术语(如果可用)和人口/身份信息组成,如下所示。
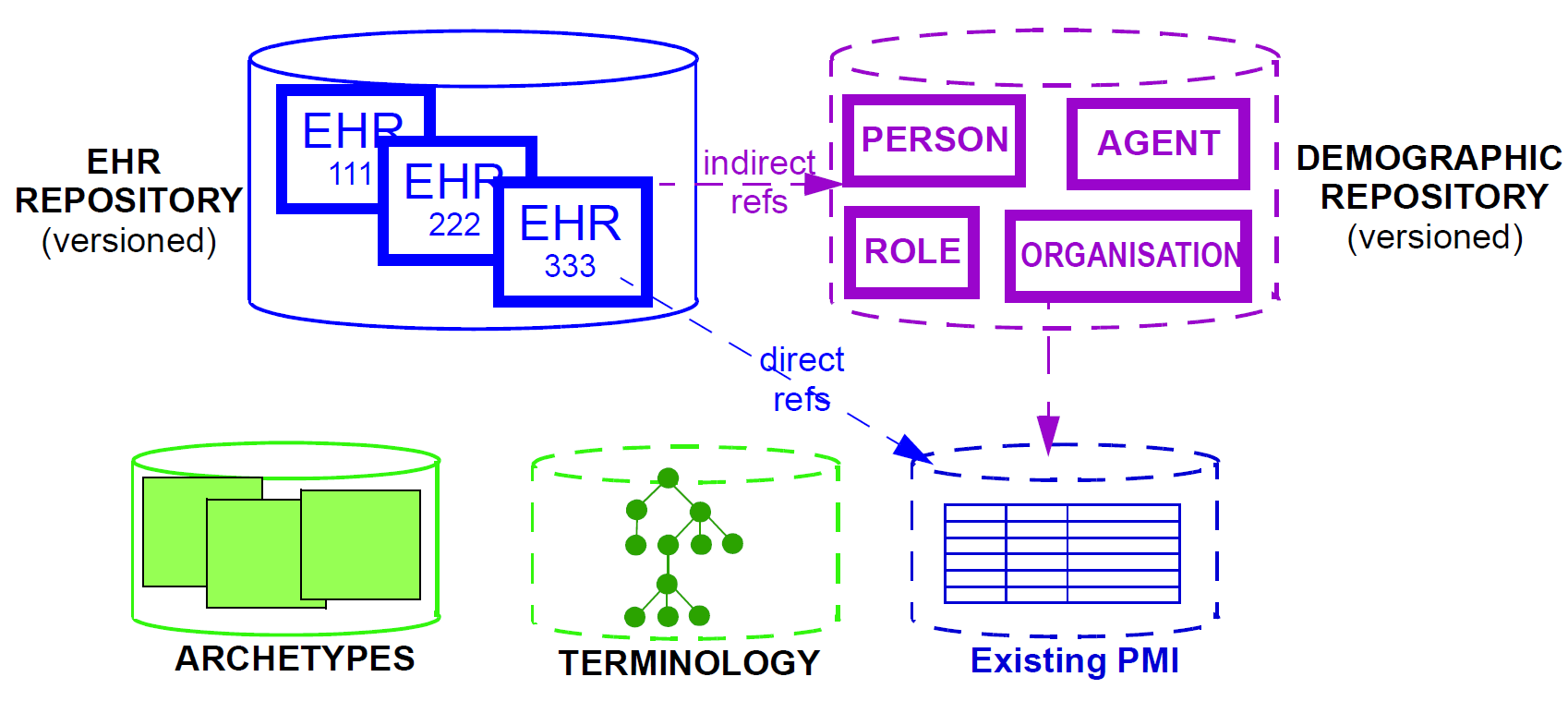
后者可以是现有PMI(患者主索引)或其他目录的形式,或者可以是openEHR人口统计库的形式。 openHHR人口统计信息库可以作为现有PMI的前端或者自己的权利。无论哪种方式,它都执行两个功能:人口统计信息结构的标准化和版本控制。 openEHR EHR包含对任何已配置为在环境中使用的人口统计资料库中的实体的引用; EHR可以被配置为不包括人口统计或一些识别数据。 openEHR的基本原理之一是完全分离EHR和人口统计信息,使得孤立的EHR对于其所属患者的身份包含很少或没有线索。安全优点如下所述。在更完整的EHR系统中,通常将部署许多其他服务(特别是与安全相关),如图7 健康信息环境所示。
如已经示出的,openEHR信息模型以不同的粒度级别来定义信息。支持和数据类型中定义的细粒度结构用于数据结构和公共模型;这些依次使用在EHR,EHR提取,人口统计和其他“顶层”模型。这些后面的模型定义了openEHR的“顶级结构”,即可以明智地独立的内容结构,并且可以被认为是面向文档的系统中的单独文档的等同物。在openEHR信息系统中,它通常是用户直接感兴趣的顶级结构。主要的顶层结构包括:
Composition: EHR的提交单元(参见EHR IM中的类型COMPOSITION); EHR Access: EHR范围的访问控制对象(见EHR IM中的EHRACCESS类型); EHR Status: EHR的状态摘要(见EHR IM中的EHRSTATUS型); Folder hierarchy: 作为EHR中的目录结构,人口统计服务(见通用IM中的类型FOLDER); Party: 各种亚型,包括ACTOR,ROLE等,代表具有身份和联系细节的人口统计实体(见类型PARTY和人口IM中的亚型); EHR Extract: EHR系统之间的传输单元,包含EHR,人口统计和其他内容的串行化(参见EHR提取IM中的类型EHR_EXTRACT)。
所有持续的openEHR EHR,人口统计和相关内容都在顶级信息结构中找到。大多数这些在以下图中可见。
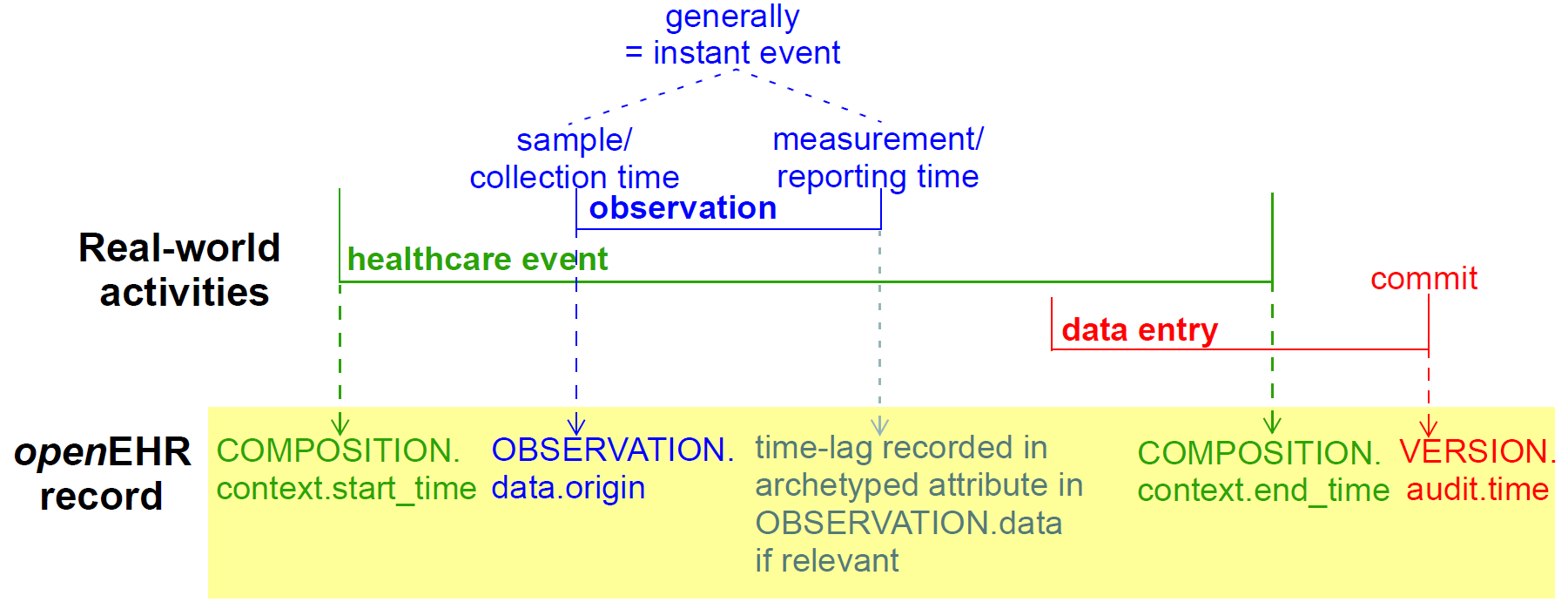
openEHR EHR是根据相对简单的模型构造的。由EHR id标识的中央EHR对象指定对多种类型的结构化版本化信息的引用,以及作为对EHR所做更改的审计的Contribution对象列表。 openEHR EHR的高级结构如下所示。
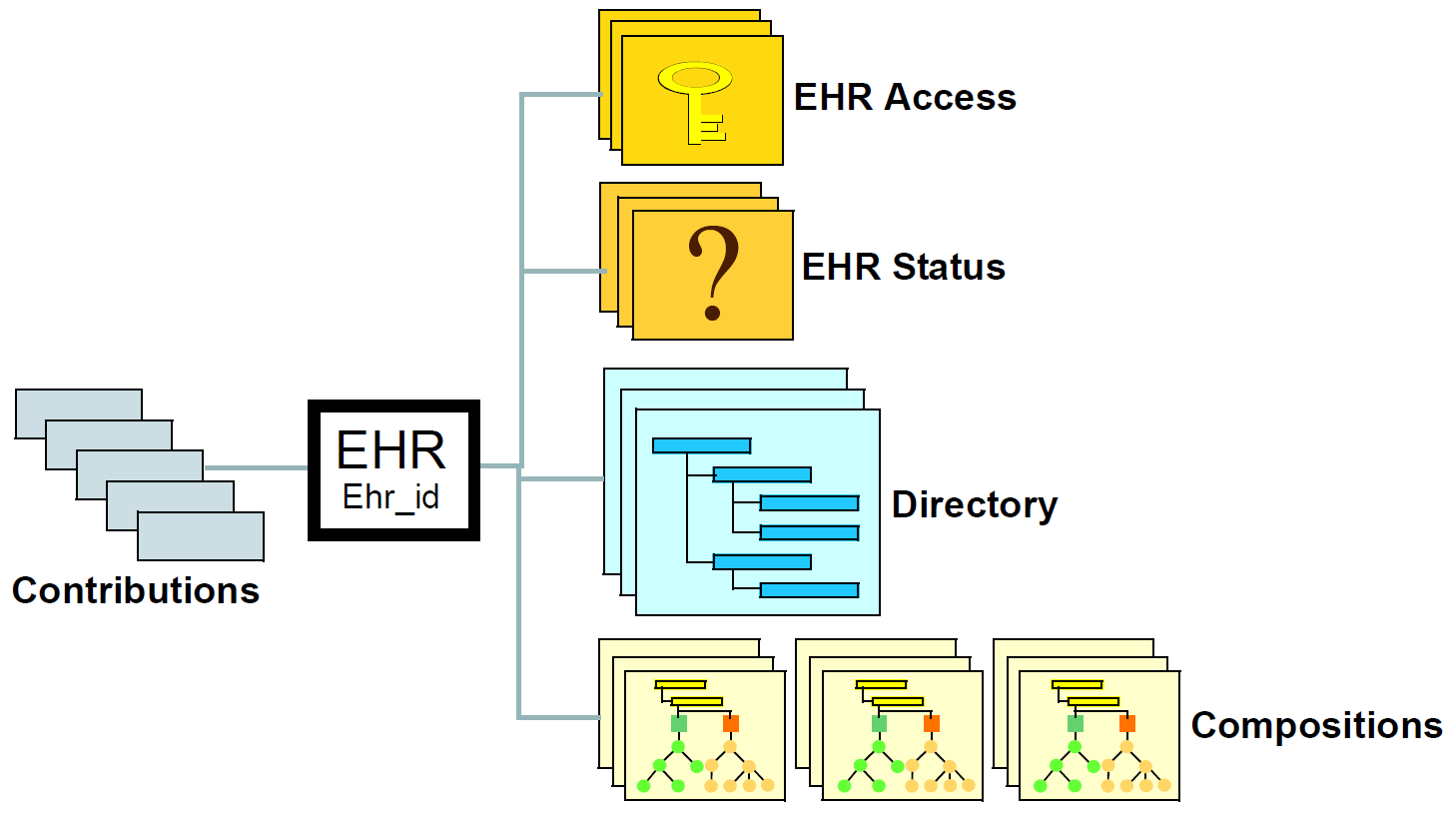
在该图中,EHR的部分如下:
组合物的内部结构以及号码簿对象与国际认可的健康信息模型(如CEN EN13606和HL7 CDA标准)的水平密切相关。
典型组合的逻辑结构在下图中更详细地显示。这显示了从组合到数据类型的各种层次级别以典型布置示出。 21种数据类型提供临床和行政记录所需的所有类型的数据。
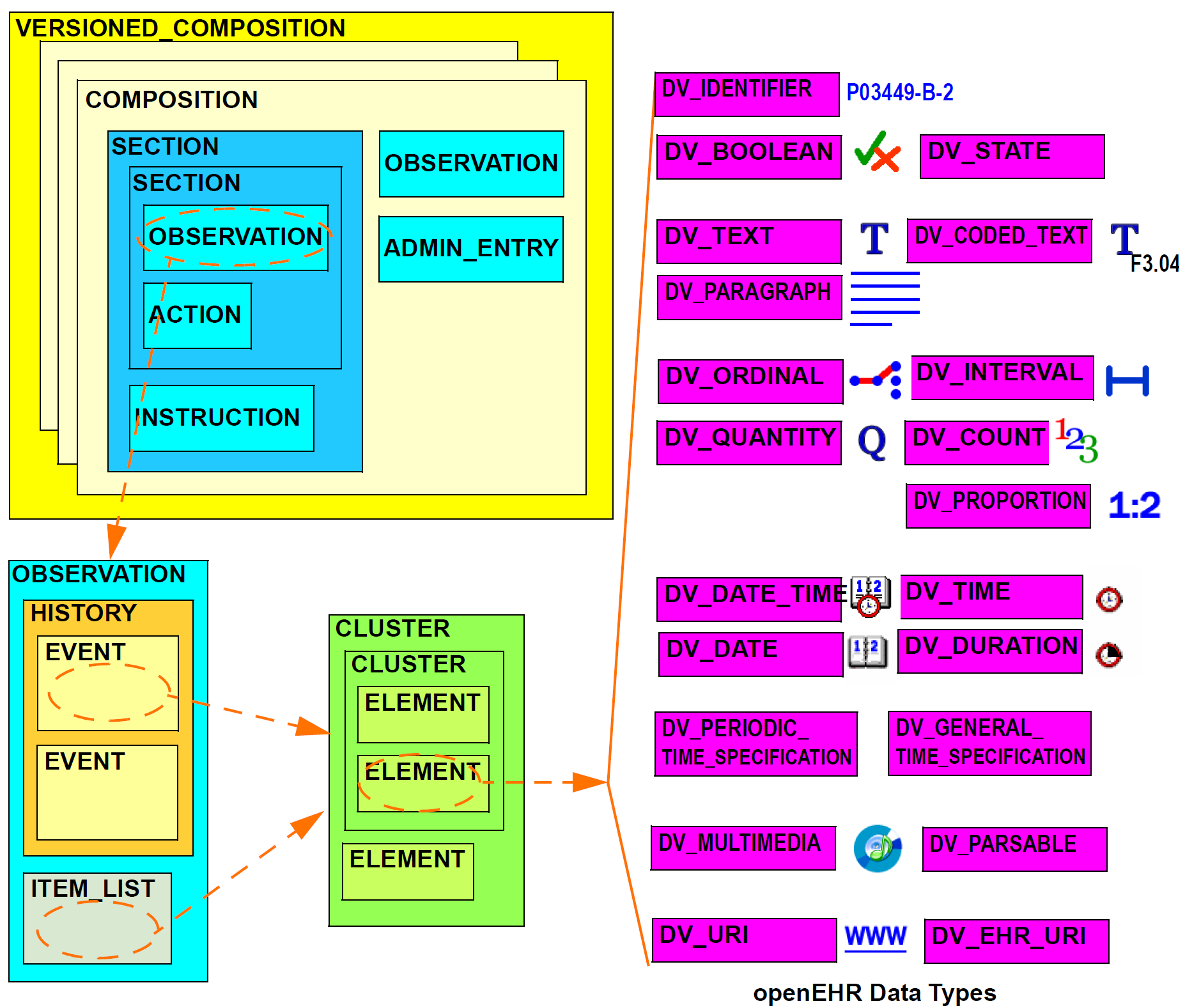
在openEHR EHR中创建的所有临床信息最终都表示在“条目”中。 条目在逻辑上是单个“临床陈述”,并且可以是单个短的叙述短语,但也可以包含大量的数据,例如, 整个微生物学结果,精神病学检查记录,复杂的药物治疗命令。 在实际内容方面,Entry类在openEHR EHR信息模型中是最重要的,因为它们定义了记录中所有“硬”信息的语义。 它们旨在被原型化,事实上,Entries和Entries的子部分的原型构成了为EHR定义的绝大多数原型。
openEHR ENTRY类如下所示。 有五个具体的子类型:ADMINENTRY,OBSERVATION,EVALUATION,INSTRUCTION和ACTION,其中后四种是CAREENTRY。

这些类型的选择基于如下所示的临床问题解决过程。
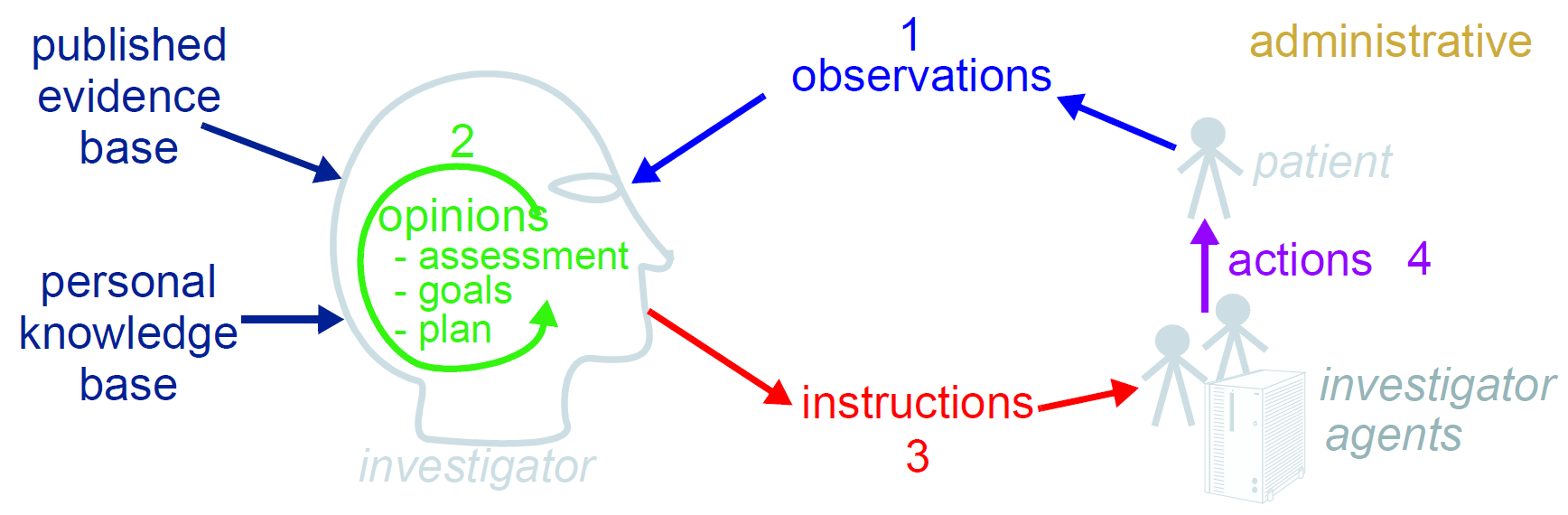
此图显示了信息创建的循环,由于迭代的问题解决过程,典型的不只是临床医学,而是一般的科学。 “系统”作为一个整体由两部分组成:“患者系统”和“临床研究者系统”。后者由健康护理人员组成,并且可以包括患者(在患者进行观察或治疗活动的时间点),并且负责理解患者系统的状态并向其提供护理。通过对下一步骤进行观察,形成观点(假设)和规定动作(指令)来解决问题,这些步骤可以是进一步研究,或者可以是被设计为解决问题的干预,以及最后执行指令(动作)。
这个过程模型是Lawrence Weed的“面向问题的”EHR记录方法的综合,以及后来的相关工作,包括Rector,Nowlan&Kay Rector_1994和“假设演绎”推理模型的模型Elstein_1987)。然而,假设制造和测试不是临床专业人员使用的唯一成功的过程 - 证据表明,许多(特别是那些更老和更有经验的)依靠模式识别和直接检索以前使用类似的患者或原型模型计划。 openEHR中使用的研究者过程模型与两种认知方法兼容,因为它不说明如何形成意见,也不暗示任何特定数量或大小的迭代使过程得出结论,甚至不需要所有步骤出现(例如,GP经常处方而不进行确切的诊断)。因此,openEHR条目模型不强加过程模型,它只提供可能发生的可能类型的信息。 条目类型的本体
在临床世界中,从业者不认为仅仅对应于上述Entry的亚型的五种数据。这些类型中有许多子类型,其中一些如下图所示。
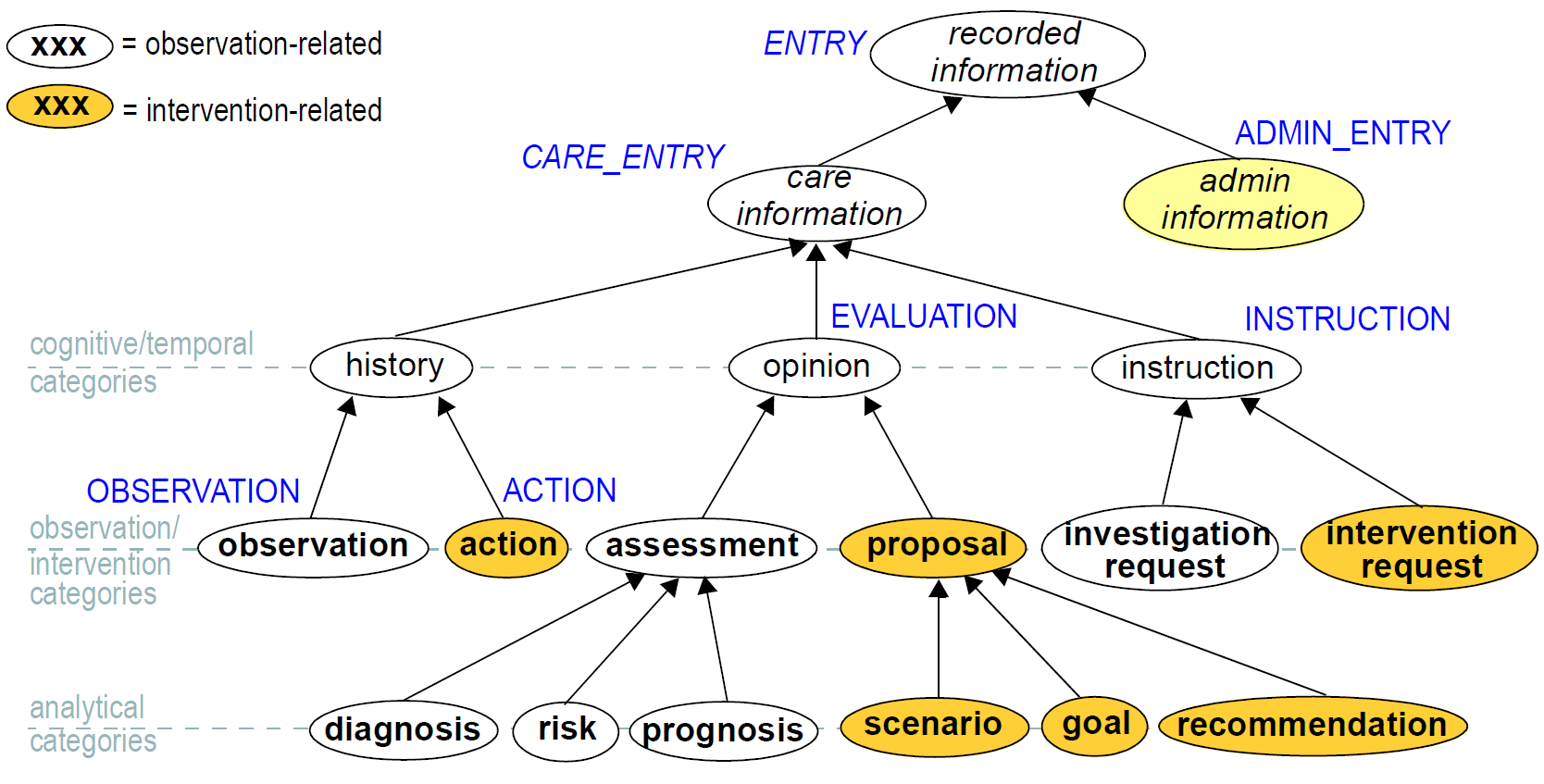
关键顶级类别是“护理信息”和“管理信息”。前者包括所有可能在护理过程中的任何时间记录的语句,并且包括Entry模型所基于的主要子类别,即“观察”,“意见”,“指令”和“动作” (一种观察),它们自身对应于过去,现在和未来的时间。行政信息类别包括不由护理过程本身产生的信息,但涉及组织它,例如约会和录取。这个信息不是关心护理,而是关于护理交付的物流。不管多样性,该图中所示的每个叶级类别最终都是来自过程模型的一种类型的子类别,因此是openEHR Entry模型的子类型的子类别。
通过使用设计用于以特定Entry子类型(在这种情况下,评估)表达感兴趣的信息(例如风险评估)的原型来实现本体中的类别的正确表示。在一个系统中,因此条目被模型化,没有错误地识别各种条目的危险,只要条目子类型,时间和确定性/否定被考虑。请注意,即使CIR_ontology图中显示的本体不正确(无疑是不正确的),原型将被构造以解释这些类别应该是什么的每个改进的想法。 临床报告状态和否定
在临床信息记录中的一个众所周知的问题是将“状态”分配给记录的项目。种类包括“P的实际值”(P代表某种现象),“P的家族史”,“P的风险”,“对P的恐惧”以及任何这些的否定,不是/没有P“,”没有P的历史“等。对这些所谓状态的适当分析表明它们根本不是”状态“,而是根据图CIR_ontology的本体的不同类别的信息。通常,通过对适当的条目类型使用“排除”原型来处理否定。例如,可以使用评估原型来建模“无过敏”,该原型描述了对于该患者排除哪些过敏。另一组可能在没有正确建模信息类别的系统中混淆的语句类型涉及干预,例如, “髋关节置换(5年前)”,“髋关节置换(推荐)”,“髋关节置换(下星期二上午10点订购)”。
所有这些语句类型以明确的方式直接映射到其中一个openEHR Entry类型,确保查询的EHR不匹配不正确的数据,例如关于恐惧或风险的语句,当查询是观察该现象时问题。
关于openEHR模型临床信息的更多细节在EHR IM文档入口部分中给出。
图clinicalinvestigatorprocess中显示的调查过程的关键部分,实际上是医疗保健,是干预。指定和管理干预(无论是最简单的处方还是复杂的手术和治疗)对于信息系统来说是一个困难的问题,因为它处于“未来时间”(意味着干预活动必须使用分支/循环时间规范来表示,而不是简单的线性意外事件可以改变事情(例如患者对药物的反应),并且给定干预的状态可能难以跟踪,特别是在分布式系统中。然而,从卫生专业人员的角度来看,几乎没有什么比想要了解的更基本:什么药物是这个病人,从什么时候,什么是进展?对这些挑战的openEHR方法是使用Entry类型INSTRUCTION,其子部分ACTIVITY指定未来的干预,以及Entry子类型ACTION以记录实际发生的情况。此模型中提供了许多重要功能,包括:
结合openEHR的全面版本化功能,指令/操作设计允许记录的临床用户在分布式环境中定义和管理患者的干预。
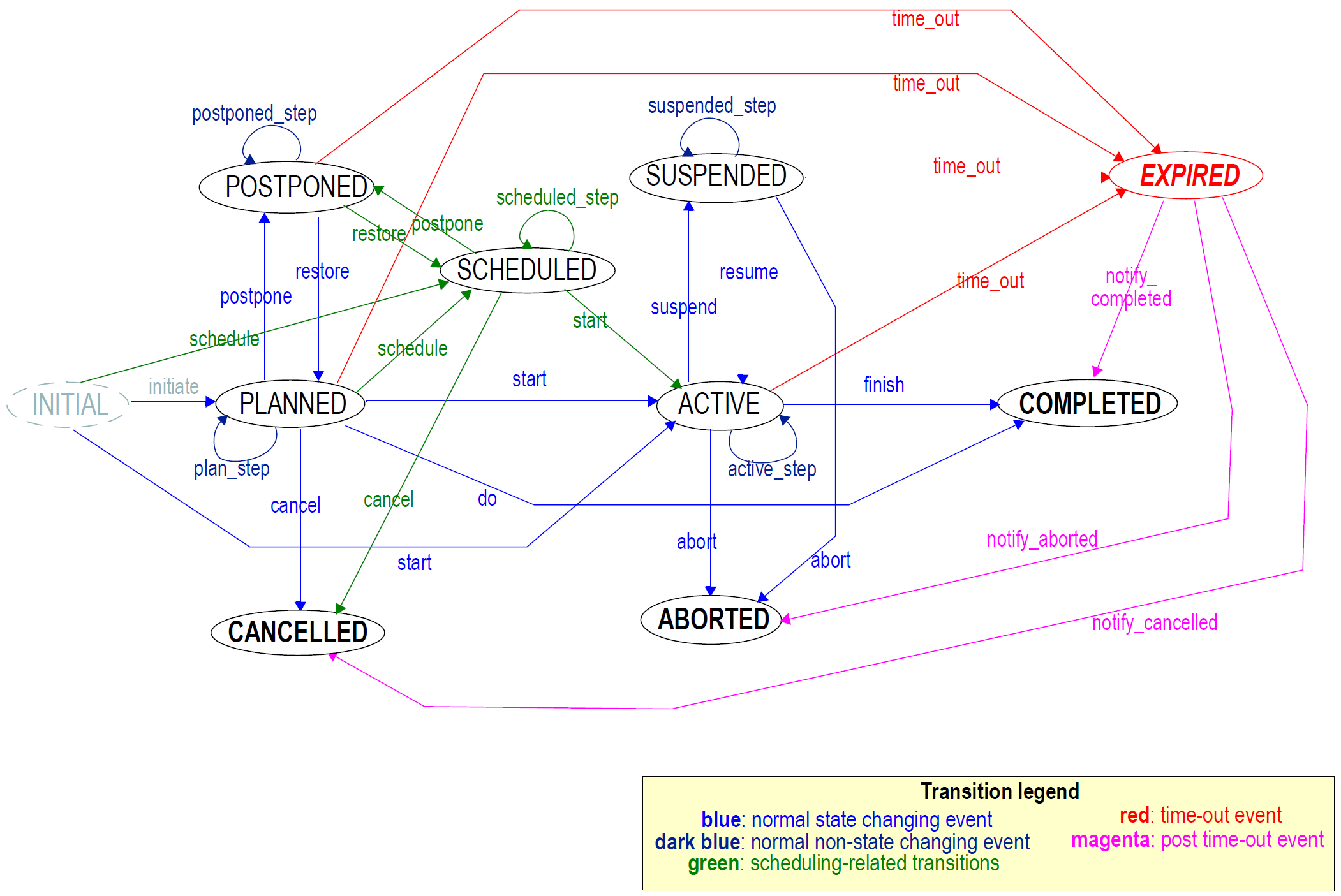
时间是众所周知的健康信息中的一个具有挑战性的建模问题。 在openEHR中,上述的调查过程(例如采样或收集时间,测量时间,保健商业事件的时间,数据提交时间)的副产品的时间被具体地建模,而特定于特定 使用通用数据属性的原型来对内容(例如,开始日期,解决日期)进行建模。 下图显示了关于观察过程的时间的典型关系,以及openEHR参考模型中的相应属性。 注意,在不同的情况下,例如GP咨询,放射报告和其他,时间关系可能与图中所示的完全不同。 时间在EHR信息模型openehrrmehr中有详细描述。
在某些情况下,在EHR中可能使用多种语言。这可能是由于跨境治疗的患者(在斯堪的纳维亚国家之间,巴西和北方邻国之间),或者由于在旅行期间接受治疗的患者,或者由于在家庭环境中使用多种语言。
openEHR EHR中的语言处理如下。整个EHR的默认语言是从操作系统区域设置确定的。如果需要,它可以包括在EHR_status对象中。然后在EHR数据中的两个地方强制地指示语言,即在语言属性中的组成和条目(即,观察等)中。这允许在EHR中不同语言的组合,以及在同一组合中不同语言的条目。此外,在条目内,如果文本和编码文本项目与封闭条目的语言不同,或者这些类型在不表示语言的其他非条目结构中使用,则文本和编码文本项目可以可选地具有记录的语言。
这些特征的使用最可能由于翻译而发生,但是在某些情况下,真实的多语言环境可能存在于临床相遇背景中。在前一种情况下,EHR的某些部分,例如特定的组合物将在临床遭遇之前或之后被翻译以使信息以EHR的主要语言可用。翻译的行为(像与EHR的任何其他交互)将以新版本的形式引起对记录的改变。新的翻译可以方便地记录为分支版本,附加到它们的翻译版本。这不是强制性的,但提供了一种方便的方式来存储翻译,以便它们不会替换原始内容。
隐私(限制谁看到个人数据的权利)和保密性(其他人尊重所披露数据隐私的义务)是许多消费者在电子卫生系统方面的主要关注点。一个被广泛接受的原则是,在一段时间的护理期间,患者向医疗专业人员提供的信息(直接地或由于样本的观察或测试等)被提供给其他方,如果患者同意;更简单地:数据共享必须由患者同意控制。对于一些患者来说,更复杂的要求是允许对其健康记录的部分进行不同的访问,例如,对大多数健康记录的相对开放的访问权限,但是对性或精神健康项目的访问有限。健康信息的相互关联可以使这很困难。例如,即使诊断是隐藏的,但是对于任何安全治疗都是需要的,并且许多卫生专业人员将看到当前药物(和过敏症)信息的不可用性对于给予甚至基本护理是非常有问题的。
另一方面,提供护理的临床专业人员希望快速访问相关数据,并且确保他们在屏幕上看到的是对患者的描述的忠实表示。护理者有时需要紧急获得健康记录,否则与患者的正常护理无关;这样的访问只能以通常的方式被同意,因为通常不知道涉及的特定提供商。
医疗保健的研究人员通常希望获得大量患者的数据,以便评估当前的护理并改善其(临床知识发现),并用于教育目的。这两个后面的需求也最终是患者和社会优先事项。因此,提供有效的护理和支持正在进行的医学研究必须在实施患者同意的概念的系统中起作用。
在理论上,患者或一些临床专业人员应该容易地指定谁可以看到患者记录。在一些情况下,其可以通过直接鉴定,例如,患者可以通过提供者id提名他们的长期GP。一些排除也可以这样做,例如,先前的医生与患者具有有问题的个人关系。然而,当患者移动到具有许多工作人员的医疗保健系统的部分中和/或没有先前建立的关系时,很快就难以单独地识别提供方。电子处方和电子药房的出现将使更多的健康和联合保健工作者进入电子健康矩阵,使个人识别谁应该看到病人的数据不可行的问题。此外,有一个大型和增长类型的“非常流动”的人(军队,艺人,非政府组织工人,国际商务和旅游专业人士,运动员...)谁也不能预测,即使在哪个国家,他们可能需要照顾。因此,在类别或角色类型方面指定一些访问控制的需求显得是不可避免的。
实现对健康信息的访问控制的困难之一是定义“角色”,即在确定访问权限时的记录的用户的状态。原则上,角色应该提前知道。例如,标签“护士”,“GP”和“精神病学家”可以相对容易地分配给个人。然而,更重要的标签的类型是在(例如)个人护理者(例如,初级GP),其他护理递送人员(例如护士,老年护理人员)和支持人员(例如病理学家,放射学家)之间区分的那些标签。在面向患者护理交付的世界观中,医疗保健专业人员的专业水平可能不如他或她与患者的当前护理过程的关系重要。
并不总是清楚哪些个人在任何时候属于这些类别中的任何一个,或者这些术语在不同地点和管辖区如何定义。实际上,在诸如“护理递送者”之类的角色类别的特定身份(例如护士在特定日子的护士上)的评估必须在每个护理递送环境中而不是在EHR中进行。因此,对于EHR中的信息的访问决定将对提供者站点知识具有某些依赖性,即哪些工作人员积极参与给定患者的护理过程。
基于角色的访问控制由于疾病或假日的临时替换以及由于人员短缺而导致的角色变化的常见事实而进一步复杂化。此外,如果采用医务秘书的医生需要她访问和更新记录的敏感部分(与他自己对病人的治疗有关),则最高级别的访问被有效地给予没有医疗训练或直接与病人的护理,即使只有10分钟。因此,任何基于角色的系统都必须考虑现实世界中临床护理的凌乱现实,而不是仅仅基于理论原则。
安全和隐私机制的可用性是健康记录架构的关键要求。由安全专家设计的一些非常优雅的细粒度访问控制的解决方案在实践中根本不可用,因为它们需要太长的时间才能使患者和医生学习,或者太费时以致不能在屏幕上实际使用;它们也可能太复杂,无法在软件中安全实现。
以下部分描述了openEHR对EHR的主要安全和隐私要求的支持。
健康记录中支持安全性和隐私性的任何模式必须基于假定威胁的某种概念。没有深入细节,openEHR假设的安全威胁包括以下(这里“不适当”是指没有或不会被患者同意的任何东西):
人为错误,导致一个患者的健康数据与另一个患者的健康数据的不正确关联。患者的误识别可能导致一个患者的个人数据进入另一个患者的记录(导致隐私侵犯和可能的临床错误),或者进入新记录,而不是针对同一患者的现有记录(导致两个或更多临床不完全记录);
健康专业人员或其他人在物理护理递送环境(包括例如医院中的任何工作人员)不适当地接近不参与当前对患者的护理;
由患者已知的其他人不适当地接近,例如家庭成员;
公司或其他组织健康数据的不当访问,例如为保险歧视目的;
恶意盗窃或获取健康数据(例如名人或政客的)以获取利润或其他个人动机;
对数据完整性和可用性的通用威胁,如病毒,蠕虫,拒绝服务攻击等;
软件故障(由于错误,不正确的配置,互操作性故障等)导致数据损坏,或不正确的显示或计算,导致临床错误。
必须牢记关于支持安全性,保密性和完整性的机制的设计的关键原则:任何给定模式的目标不适当访问的可能性与信息的感知价值成比例,并且与访问成本成反比。为了解释Ross Anderson的BMA论文Anderson_1996关于健康数据安全,对于给定的访问,实施者将尝试找到最简单,最便宜和最快捷的方法,这比James Bond启发的技术更可能是贿赂或爆窃。 openEHR通过提供一些相对简单的机制来利用这一原理,这些机制实现起来很便宜,但是可以使得误用非常困难,而不会影响可用性。
许多与安全和隐私相关的具体机制存在于系统部署中,而不是在诸如openEHR的模型中,特别是在认证,访问控制和加密的实现中。 openEHR规范和核心组件实现没有明确定义许多具体机制,因为不同站点的需求有很大的差异 - 安全的局域网部署很多需要最小的安全性,而可访问的健康记录服务器可能有不同的要求。 openEHR所做的是以足够灵活的方式支持一些关键需求,使具有显着不同需求和配置的部署仍然能够以标准方式实现基本原则。
下图说明了openEHR架构直接指定的主要安全措施。这些包括EHR /人口统计分离和EHR范围的访问控制对象。在版本化对象级别,提交审计(强制),数字签名和散列可用。以下小节更详细地描述这些特征。
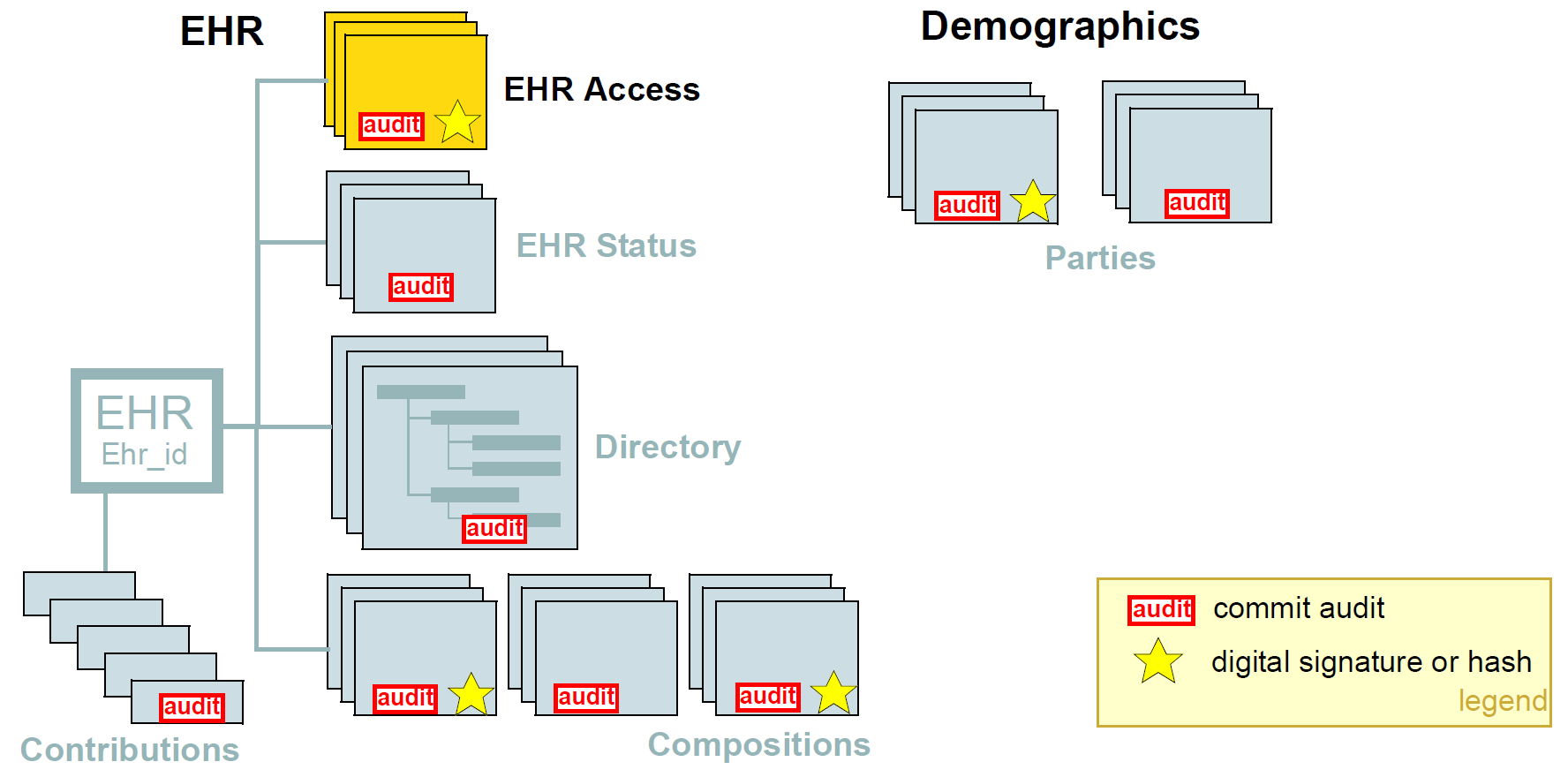
本身,openEHR EHR只施加一个最小的安全策略配置文件,可以被认为是必要的,但是对于部署的系统通常是不够的(即,其他方面仍然需要在其语义未在openEHR中定义的层中实现) 。以下政策原则体现在openEHR中。
一般
不可磨灭
审计尾随
匿名
访问控制
访问列表
访问控制访问设置
隐私
可用性
应该在即使最小的EHR部署中实现但未由openEHR直接指定的其他安全策略原则包括以下内容。
访问日志记录
记录拆分
记录合并
访问时间限制
不可否认
认证
策略的一个关键特征是它必须扩展到分布式环境,其中在由患者访问的多个提供者站点维护健康记录信息。
正如安德森在BMA研究中指出的,还需要政策要素来防止用户访问大量的EHR,并推断攻击。目前,这些都在openEHR的范围之外,并且现实地,在当今的任何种类的大多数EHR实现。
以下部分描述了openEHR如何支持第一个策略目标列表。
openEHR最基本的安全相关特性是它支持数据完整性。这主要由版本控制模型提供,在通用信息模型中的change_control包中和提取信息模型中指定。基于变更集的版本控制EHR和人口统计服务中的所有信息构成了信息的基本完整性度量,因为没有内容被物理修改,只创建了新版本。因此,所有逻辑更改和删除以及添加物理实现为新版本,而不是对现有信息项的更改。显然,信息的完整性将取决于执行的质量;然而,由于是一次写入系统,最简单的可能实现(1版本= 1拷贝)可以提供非常好的安全性。
在openEHR中称为贡献的改变集的使用提供了与由用户在单个工作单元中修改,创建或删除的所有项目相对应的另一个完整单元。
openEHR版本控制模型定义所有已更改项目的审计记录,这些记录可以是基本审计和/或任何数量的附加数字签名证明(例如由高级工作人员)。这意味着使用用户标识,时间,原因和可能的其他元数据记录对openEHR记录的任何部分的任何类型的每个写入访问。
在openEHR EHR中存在对版本化对象中的每个版本(即,对于任何逻辑项目的每个版本,例如药物列表,遇到的注释等)进行数字签名的可能性。签名被创建为正被提交的版本的规范表示(例如在基于模式的XML中)的散列(例如MD5)的私钥加密(例如RSA-1)。在openEHR中定义签名和摘要字符串的一个可能的候选是openPGP消息格式(IETF RFC2440 [rfc_2440]),因为它是一个开放的规范和自我描述。 RFC2440对格式的使用并不意味着使用PGP分布式证书基础结构,或任何认证基础结构; openEHR在这一点上是不可知的。如果没有公钥或等效基础结构可用,则可以省略加密步骤,从而仅摘要内容。签名存储在版本对象中,允许它方便地携带在EHR提取内。过程如下图所示。
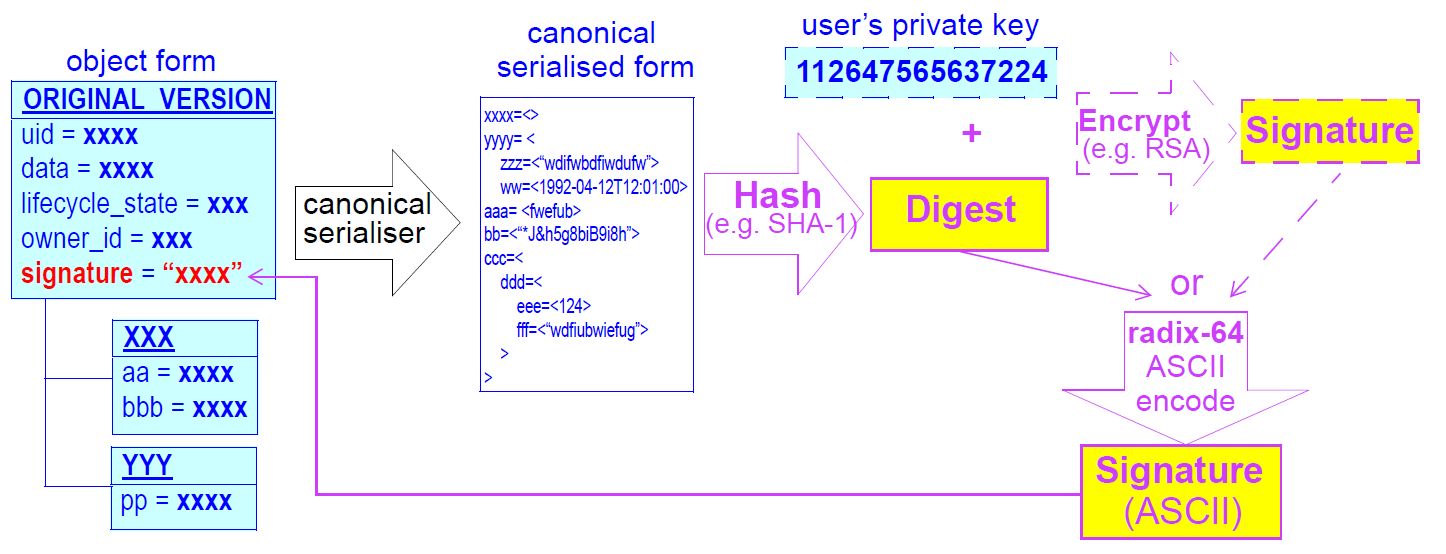
版本化系统中的数据签名用作完整性检查(摘要执行此功能),认证措施(签名执行此功能)以及不可否认性测量。为了防止对版本化的持久层本身的黑客攻击,可以将签名转发到可信的公证服务。基于数字签名的完全安全的系统还需要经过认证的公钥,在任何给定环境中都可以使用或不使用。
数字签名相对较小的EHR(单个版本)而不是整个EHR或其大部分的好处之一是项目的完整性更不受局部存储库损坏的影响。
如上文6.1节所述,openEHR EHR的特征之一是分离EHR(临床和管理)信息和人口统计信息。这主要涉及对患者而不是提供者实体的引用,因为提供者实体通常是公知的。 openEHR中称为PARTYSELF的特殊类型的对象用于引用EHR中的主题。 PARTYSELF实例中包含的唯一信息是可选的外部引用。 openEHR EHR可以配置为通过控制在PARTY_SELF实例中实际设置的外部标识符是否以及在何处设置,从而提供3级分隔,如下所示:
EHR中没有地方(即每个PARTYSELF实例都是空白占位符)。这是最安全的方法,并且意味着EHR和患者之间的链接必须在EHR外部通过关联EHR.ehrid和主体标识符来完成。这种方法更可能用于更开放的环境。
一次只在EHR_STATUS对象(subject属性)中,而没有其他地方。如果EHR状态对象以某种方式受到保护,这也是相对安全的。
在每个PARTY_SELF实例中;此解决方案在安全环境中是合理的,并且便于在本地周围复制记录的部分。
这种简单的机制提供了针对某些类型的信息窃取或黑客(如果使用得当)的基本保护。在最安全的情况下,黑客不仅必须窃取EHR数据,还要窃取单独的人口统计记录和身份交叉参考数据库,这两者都可以位于不同的机器上(使盗窃更难)。身份交叉引用数据库将很容易被其他安全机制加密或保护。
访问控制在EHR的EHR_ACCESS对象中的openEHR EHR中完全指定。此对象充当所有信息访问的网关,并且任何访问决策必须基于其包含的策略和规则。
定义EHR Access对象的语义的一个问题是,目前没有公开的正式的,已经证明的用于共享健康信息的访问控制的模型。正在进行的各种工作包括CEN EN13606第4部分工作,基于通用安全标准ISO / IEC 17799在TC / 215中完成的ISO PMAC(特权管理和访问控制)工作。毫无疑问,实验性甚至一些有限的生产健康信息安全实施存在。然而,在现实中,没有大规模的共享EHR部署,因此迄今的安全解决方案仍然是发展的。
因此,openEHR体系结构设计为适应访问控制的替代模型,每个模型由类ACCESSCONTROLSETTING(安全IM)的子类型定义。这种方法意味着可以初始地定义和实现简单的访问控制模型,稍后使用更复杂的模型。在任何给定时间使用的“方案”总是在EHR Access对象中指示。
版本控制是openEHR架构的一个组成部分。用于EHR或人口统计信息的openEHR仓库作为变更控制的“版本容器”集合(由common.changecontrol包中的VERSIONEDOBJECT
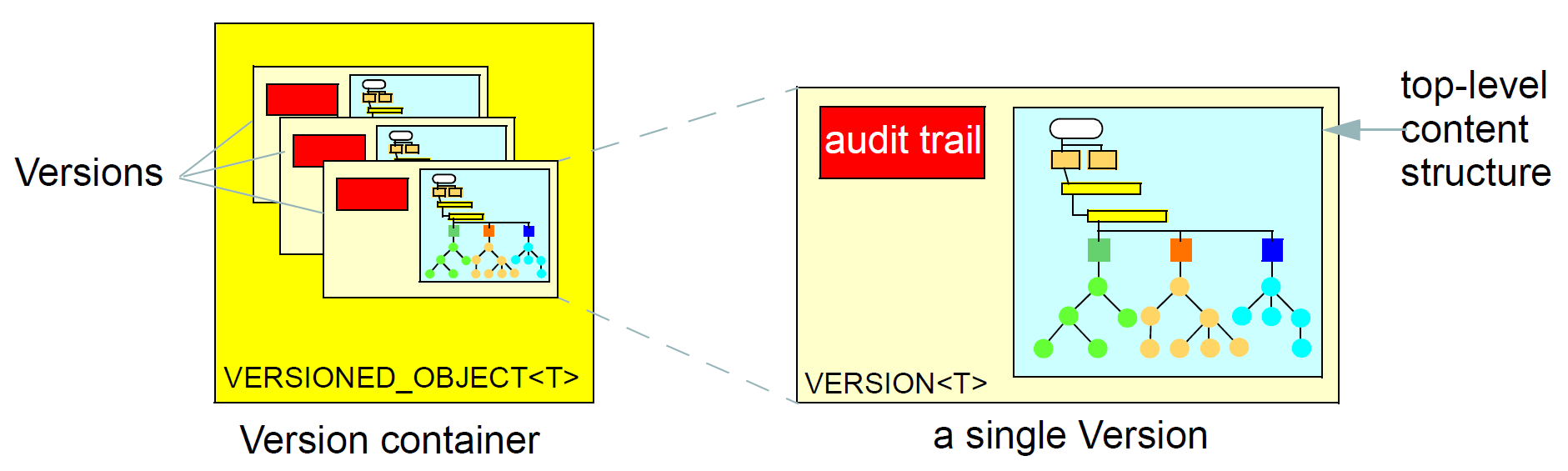
单个顶级结构的版本化是必需的,但对于必须提供连贯性,可追溯性,不可消除性,回滚和对数据的过去状态的取证检查的支持的存储库来说不是足够的要求。还需要支持“更改控制”的功能。根据一个有纪律的变更控制计划,不会对单个顶层结构,而是对储存库本身进行任意更改。更改采用称为“贡献”的更改集的形式,由存储库中受控项目的新版本或更改版本组成。变更集的关键特性是它的行为就像一个事务,并且从一个一致的状态到另一个状态,而任意组合的单个控制项的变化很容易不一致,甚至危险的错误,临床数据。
这些概念在配置管理(CM)中是众所周知的,并且被用作大多数软件和其他变更管理系统的基础,包括当今可用的许多免费和商业产品。它们是openEHR架构的中心设计特性。以下部分提供了更多详细信息
“配置管理”(CM)范例在软件工程中是众所周知的,并且具有其自己的IEEE标准IEEE_828。 CM是关于对项目(正式地称为“配置项”或CI)的储存库的改变的管理控制,并且与随时间变化的不同信息项的任何逻辑储存库相关。在卫生信息系统中,至少两种类型的信息需要这样的管理:电子健康记录和人口统计信息。在过去的大多数分析中,对于变更管理的需求已经根据对变更的审计拖延,存储库的先前状态的可用性等的具体要求来表示。在openEHR中,目的是提供一个用于变更控制的正式的通用模型,并显示它如何应用于健康信息。
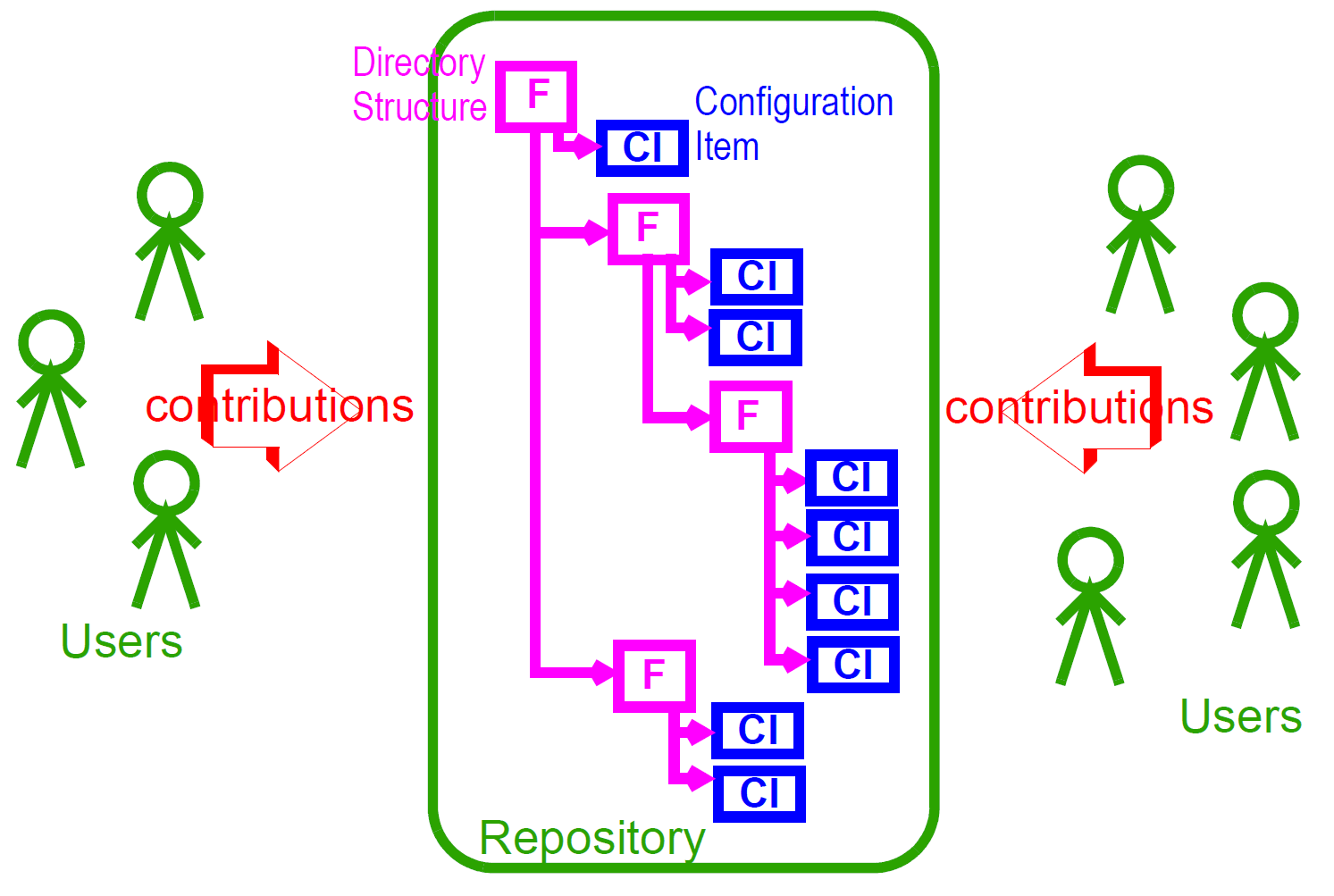
诸如软件存储库或EHR的复杂信息项的存储库的一般组织包括以下:
多个不同的信息项或配置项,每个都被唯一地标识,并且可以具有任何数量的内部复杂度;
可选地,其中组织了配置项的某种目录系统;
可能与正确解释主要版本项目相关的其他环境信息,例如,用于创建它们的工具的版本。
在软件或文档存储库中,CI是布置在文件系统的目录中的文件;在基于openEHR的EHR中,它们是组合,可选的文件夹结构,人口统计服务中的各方等等。用户对存储库做出贡献。这个一般抽象可视化如下。
对隔离的配置项不会发生更改,而是整个存储库。可能的更改类型包括:
创建新的CI;
去除CI;
修饰CI;
创建,更改或删除部分目录结构;
将CI移动到所述目录结构中的另一位置;
证明现有的CI。
配置管理的目标是确保以下内容:
存储库始终处于有效状态;
可以重建储存库的任何先前状态;
所有更改都是审计跟踪的。
正确管理存储库的更改需要两个机制。第一个版本控制,用于管理每个CI的版本和目录结构的版本(如果有的话)。第二个是“变更集”的概念,称为openEHR中的贡献。这是由用户作为某些逻辑更改的一部分对单个配置项(以及EHR中的其他顶级结构)的一组更改。例如,在文档存储库中,逻辑更改可能是对由多个文件(CI)组成的文档的更新。有一个贡献,包括对文档文件CI的更改,到存储库。在EHR中,贡献可能包含对多个组合的更改,并且可能包括组织的文件夹结构。对EHR的任何更改都需要贡献。供稿中受影响的项目可能发生的更改类型有:
添加新项:创建新的版本容器,并且向其添加第一版本;
删除项:将其数据属性设置为Void的新版本添加到现有版本容器中;
修改项目:将其数据包含项目内容的更新形式的新版本添加到现有版本容器(这可以对逻辑更新或校正进行);
import of item:创建一个新的“import”版本,包含收到的版本;
项目的认证:将新的认证添加到现有版本的认证列表中。
下图中说明了对存储库的一个典型的更改顺序。
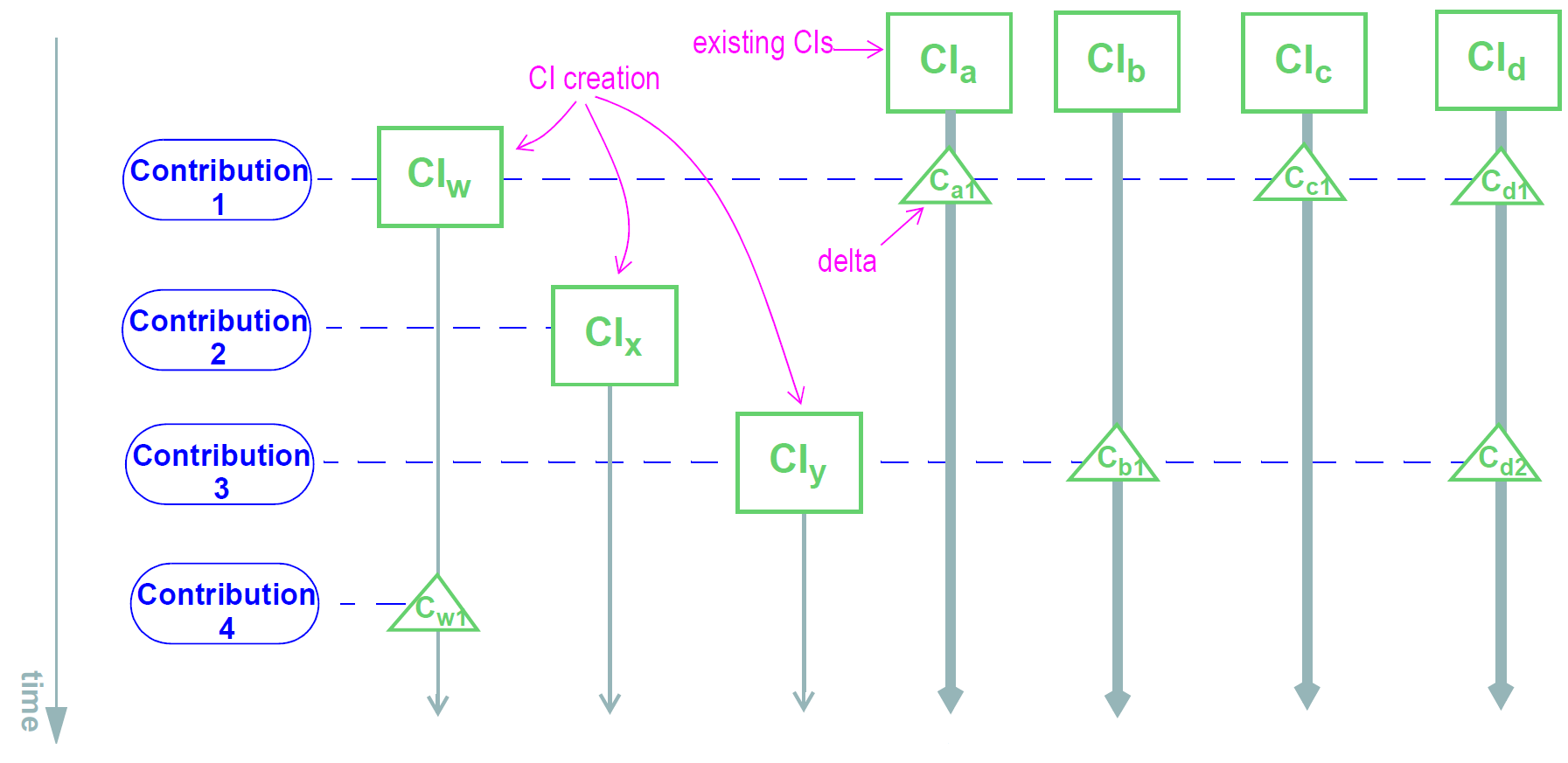
这显示了四个贡献(由左侧的蓝色椭圆指示)对包含多个CI的存储库的影响(为了简单起见,不显示目录树)。随着每个贡献,存储库以某种方式改变。第一个引入现有的新的CI,并修改三个其他(由'C'三角形指示的更改)。第二个贡献仅导致创建新的CI。第三个导致创建以及两个改变,而第四个导致仅改变。 (此处不显示文件夹结构的更改)。
应当指出的一个细节是,在上图中,贡献被示为如果它们字面上是一组增量,即恰好是记录发生的改变。因此,第一贡献是集合{CIw,Ca1,Cc1,Cd1}等等。这是否真的取决于持久性解决方案的构造。在一些情况下,一些CI可以由查看当前列表的用户更新,并且仅输入改变 - 上面所示的情况;在其他实施例中,系统可以提供这些CI的当前状态以供用户编辑,并且提交更新的版本,如下图所示。某些应用程序可以同时执行,具体取决于要更新哪个CI。内部版本化实现可以或可以不生成增量作为高效存储的方式。
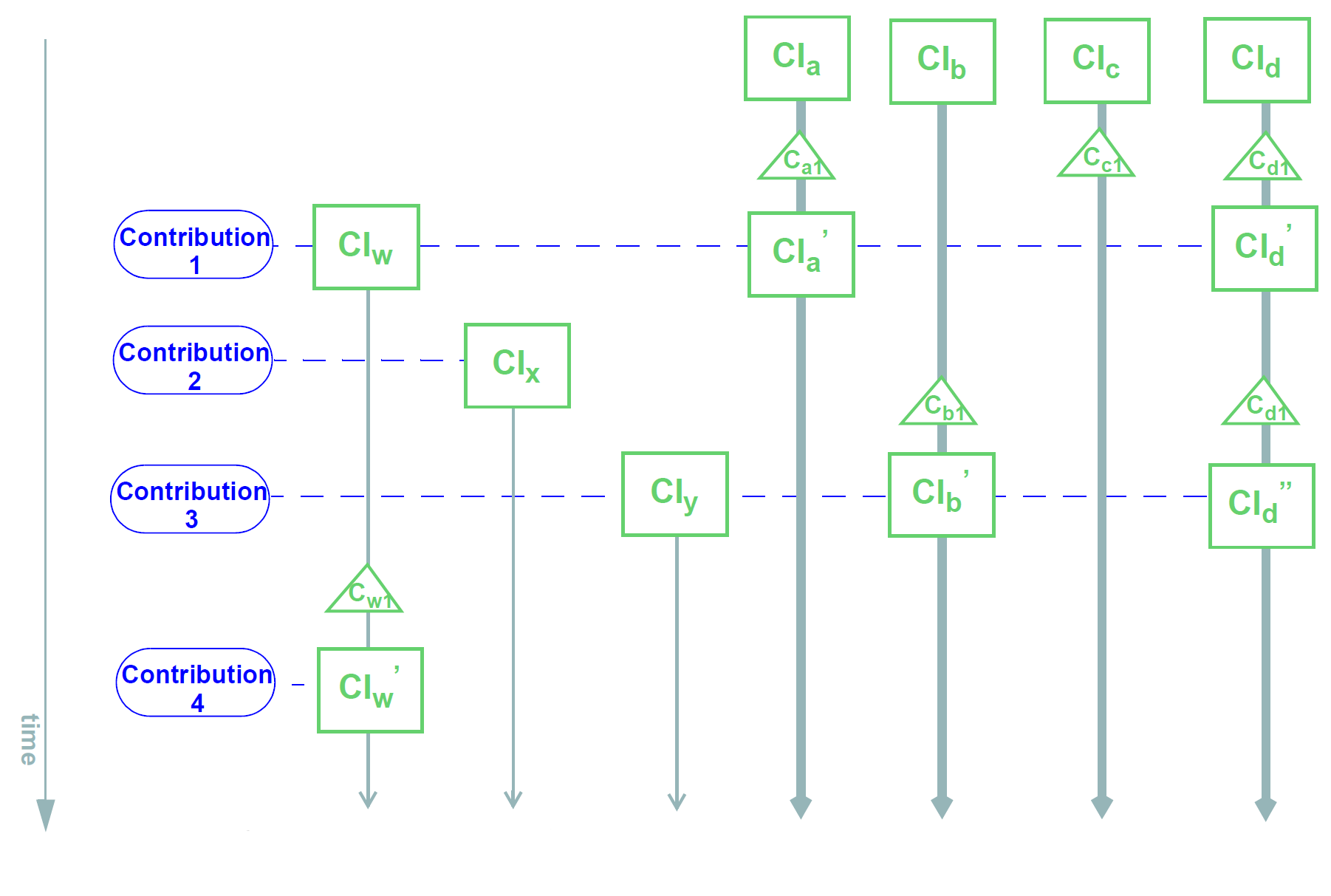
为了openHHR的目的,贡献被认为是一次创建或证明的一组版本,如上图所暗示的。
下图显示了变更控制存储库的抽象模型。
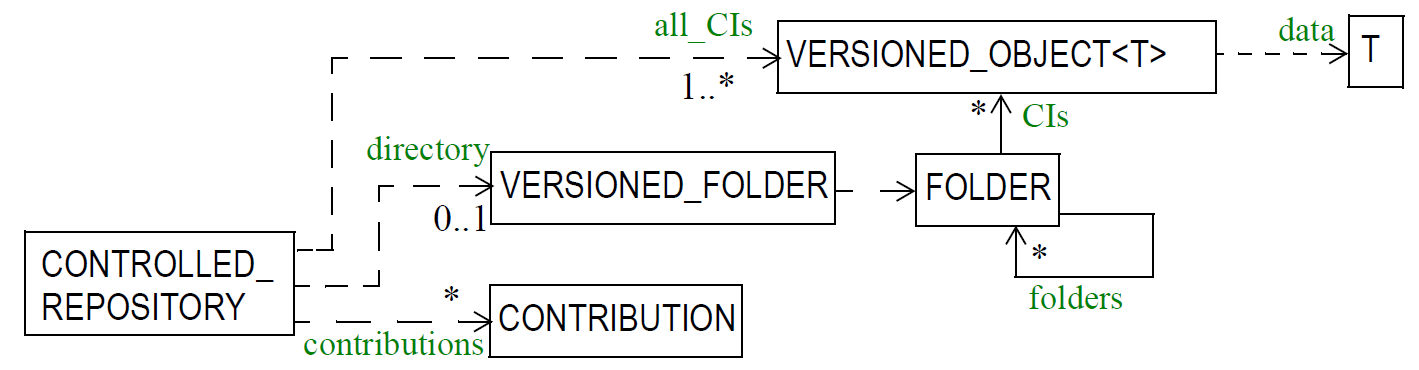
这包括:
版本控制的配置项 - VERSIONED_OBJECT
贡献;
文件夹的可选目录系统。如果使用文件夹,则文件夹结构也必须作为一个单元版本化。
受控存储库和其他实体之间的实际链接类型可能不同 - 在某些情况下,它可能是关联,在其他实体聚集;基数也可能不同。因此,上图提供了实际控制存储库定义的指南,例如EHR,而不是它们的正式规范。
在openEHR中定义的版本化模型的底层设计概念被称为“虚拟版本树”。这个想法在抽象中很简单。信息以块的形式提交到存储库(例如EHR),每个块是一个版本的“数据”。每个版本在版本树中有其位置,版本树又在版本树对象(或“版本容器”)内部维护。虚拟版本树概念意味着任何给定的Versioned对象在各种系统中可以具有多个副本,并且在每个版本中创建版本以这样的方式完成:所创建的所有版本实际上与“虚拟”版本树兼容从所有副本的版本树的叠加。这是使用用于版本识别的简单规则来实现的,并且是为了促进数据共享。虚拟版本树概念提供了两个非常常见的场景:
在一个或多个护理交付组织中创建和维护作为患者的状态或情况的代理的纵向数据,例如“药物”或“问题列表”(openEHR中的持久性组成),并且跨越更大数量组织;
在一个位置中的EHR服务器中的一些EHR被镜像到一个或多个其他EHR服务器中(例如在相关患者也被治疗的护理提供者处);镜像过程要求服务器之间的异步同步无缝工作,而不管创建的任何数据的位置,时间或作者。
openEHR中使用的版本控制方案保证无论数据在哪里创建或复制,由于共享,没有不一致,并且明确表示逻辑副本。因此,它为共享保护环境中的共享数据提供了直接支持。
在openEHR系统中,每个EHR具有在每个EHR的根EHR对象中找到的唯一标识符,称为EHR id。 EHR ID应为“强”全局唯一标识符,例如可靠创建的Oids或Guids。没有一个系统应该包含同一主题的两个EHR。如果不是这种情况,则意味着EHR系统未能检测到主体的EHR的存在,或者未能将所提供的人口统计属性与主体匹配。
在分布式环境中,EHR id与受试者(即患者)的对应是可变的,并且取决于环境的整合水平。在非集成或偶尔连接的环境中,相同的患者可能在每个机构具有单独的EHR,每个具有其自己的唯一EHR ID,但相同的主体ID。如果另一个提供者请求在一个位置处的患者EHR的部分的副本,则所接收的项目将被合并到该患者的本地EHR中。在这种情况下持久性构成的合并可能需要人为干预。在分布式环境中每个患者的多个EHR ID是缺乏系统连接或识别服务的证据。
在完全集成的分布式环境中,典型的患者仍然在多个位置具有本地EHR,但是每个携带相同的EHR ID。当患者在新位置呈现时,可以对环境的识别服务做出请求以确定是否已经存在该患者的EHR。如果存在,则可以制作全部或部分现有EHR的克隆,或者可以创建新的空EHR,但是在所有情况下,EHR ID将与用于同一患者的其他位置中的EHR ID相同。
注意,上述逻辑仅在每个位置中的EHR是openEHR EHR的情况下成立。
虽然openHHR不能完全确定EHR的识别,但是EHR中项目的识别是完全定义的。这里描述的方案需要两种“标识符”:标识符和引用,或定位符。标识符是给予对象的唯一(在一些上下文中)符号或数字,并且通常写入对象,而引用是外部对象使用标识符来引用包含所讨论的标识符的对象。这种区别与关系数据库系统中主键和外键之间的区别相同。
在openEHR RM中,标识符和引用用在support.identification包中定义的两组类实现。各种类型的标识符由OBJECTID的后代类定义,而引用由从OBJECTREF继承的类定义。区别如下图所示。这里我们看到两个具有OBJECTID的容器对象(因为OBJECTID是一个抽象类型,实际类型是另一个XXXID类),以及各种OBJECTREF作为引用。
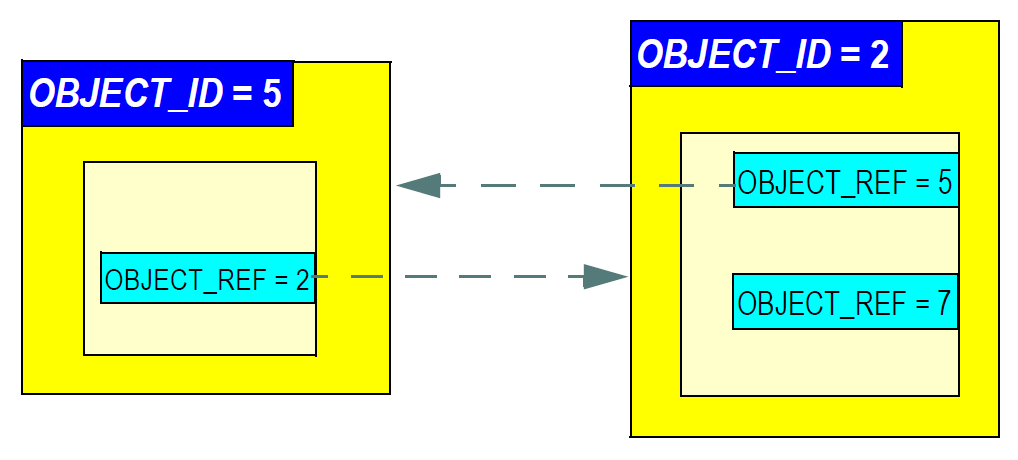
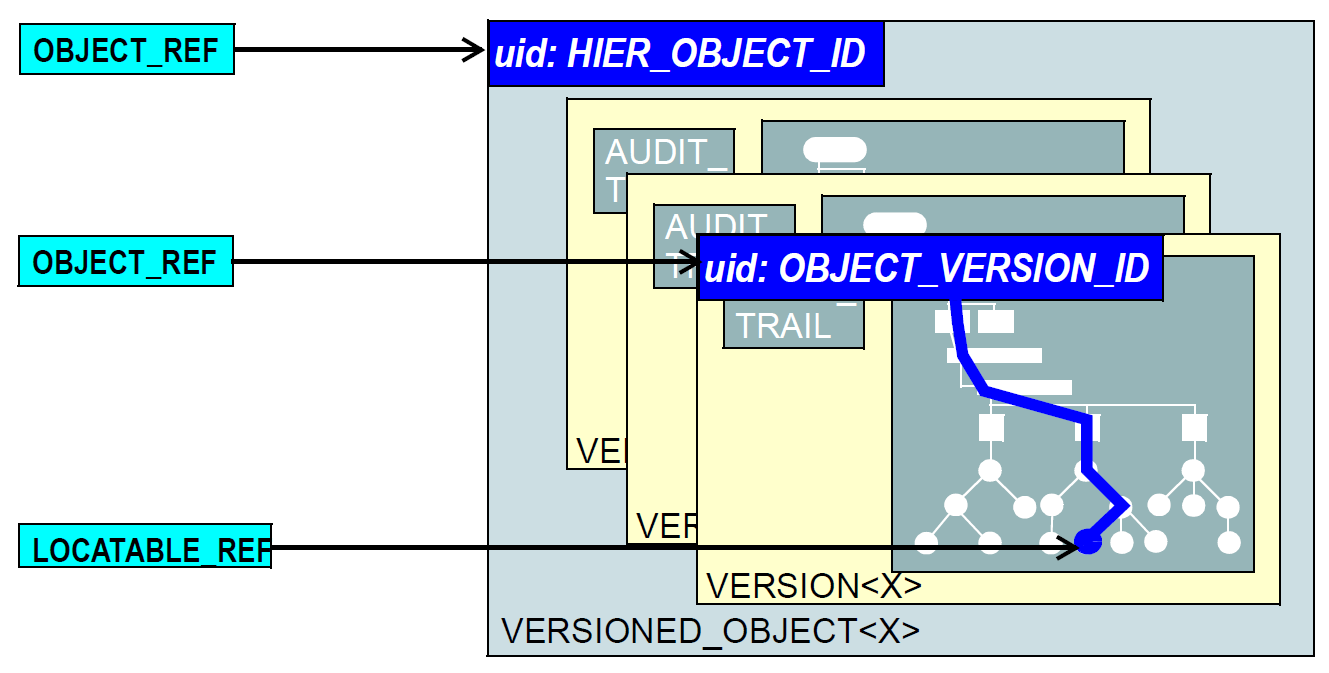
为了使数据项从外部可定位,在openEHR中的3个级别支持标识,如下:
版本容器:VERSIONED_OBJECTs(公共IM)唯一标识;
顶级内容结构:诸如COMPOSITION,EHRSTATUS,EHRACCESS,PARTY等内容结构通过其包含VERSIONED_OBJECT的标识符与其在容器内的包含VERSION的标识符的关联而唯一地标识;
内部节点:使用路径标识顶层结构中的节点。
分别使用三种识别。对于版本容器,使用无意义的唯一标识符(“UID”)。在大多数情况下,将使用类型HIEROBJECTID,其包含UID类的子类型的实例,即ISO OID或IETF UUID(参见rfc_4122;也称为GUID)。通常,UUID是有利的,因为它们不需要中心分配并且可以在现场生成。然后可以使用包含其标识符的OBJECT_REF引用版本化容器。
顶层结构的版本以确保即使在发生复制,合并和随后修改的分布式环境中也能工作的方式来标识。顶级结构的一个版本的完整标识是由所拥有的VERSIONEDOBJECT的uid和两个VERSION属性creationsystemid和versiontreeid组成的全局唯一元组。 creationsystemid属性携带首次创建内容的系统的唯一标识符;这可以是GUID,Oid或反向因特网标识符。 versiontree_id是1或3部分号码字符串,例如“1”或分支,“1.2.1”。典型的版本识别元组如下:
F7C5C7B7-75DB-4b39-9A1E-C0BA9BFDBDEC -- id of VERSIONED_COMPOSITION
au.gov.health.rdh.ehr1 -- id of creating system
2 -- current version
这个3部分元组被称为“版本定位器”,并且由support.identification包中的类OBJECTVERSIONID定义。可以使用包含版本的OBJECTVERSIONID的副本的正常OBJECTREF来引用VERSION。 openEHR版本识别方案在Common IM的changecontrol包部分中有详细描述。
识别的最后一个组成部分是路径,用于指代由其版本定位符标识的顶级结构的内部节点。 openEHR中的路径遵循Xpath样式语法,在最常见的情况下会缩短路径的略有缩写。路径在下面详细描述。为了从顶层结构的外部引用内部数据节点,需要版本定位符和路径的组合。这在支持IM的标识包中的LOCATABLEREF类中正式化。还可以使用通用资源标识符(URI)形式,由数据类型DVEHRURI(openehrrmdata_types)定义。这种类型在方案 - 空间“ehr:”中提供了单个字符串表达式,它可以用于从任何地方(也可以用于表示查询;参见下文)引用内部数据节点。任何LOCATABLEREF可以转换为DVEHRURI,但并不是所有DVEHRURI都是LOCATABLE_REF。
下图总结了各种类型的OBJECTID和OBJECTREF如何用于标识对象,以及从外部引用它们。
在二级建模方法下,信息结构的形式定义发生在两个层次。较低的级别是参考模型,一个稳定的对象模型,从中可以构建软件和数据。 openEHR参考模型中的概念是不变的,包括组合,节,观察和各种数据类型(如数量和编码文本)。上层由原型和模板形式的域级定义组成。在此级别定义的概念包括诸如“血压测量”,“SOAP标题”和“HbA1c结果”之类的内容。
符合openEHR参考模型(RM)的所有信息 - 即信息模型(IM)的集合 - 是“可构建的”,意味着内容的创建和修改以及数据的后续查询可由原型控制。原型本身与数据分离,并存储在它们自己的存储库中。在任何特定位置的原型仓库通常将包括来自公知的在线原型库的原型。原型在运行时通过指定用于特定目的的特定原型组的模板来部署,通常对应于屏幕形式。
原型本身是一个原型模型的实例,它定义了一种用来编写原型的语言;该模型的语法等价物是原型定义语言ADL。这些形式主义分别在openEHR原型对象模型(AOM)和ADL文档中指定。每个原型是对参考模型的一组约束,定义被认为符合原型主题的实例子集,例如。 “实验室结果”。原型因此可以被认为是类似于LEGO®说明书(例如用于拖拉机),其限定了构成拖拉机的LEGO砖的构造。原型是灵活的;一个原型包括许多变体,与LEGO®指令可能包括同一基本对象的多个选项的方式相同。在数学上,原型等价于F逻辑中的查询KiferLausenWu_1995。
在范围上,原型是通用的,可重用的和可组合的。为了数据捕获和验证目的,它们通常在运行时通过模板使用。 openEHR模板是定义一个或多个原型的树的规范,每个原型限制各种引用模型类型的实例,如组合,节,入口子类型等。因此,虽然可能存在诸如“生物化学结果”(观察原型)和“SOAP标题”(部分原型)之类的事物的原型,但是模板用于将原型放在EHR中形成整个组合物,例如。 “出院总结”,“产前检查”等。模板通常与屏幕形式,打印报告,以及一般来说,完全应用级的要捕获或发送的信息块紧密对应;它们因此可以用于定义消息内容。它们通常在本地开发和使用,而原型通常广泛使用。
运行时使用模板来创建默认数据结构并验证数据输入,确保EHR中的所有数据符合模板引用的原型中定义的约束。特别地,它符合原型的路径结构,以及它们的术语约束。在数据创建时使用的原型在数据中以在相关根节点处的原型标识符和原型节点标识符([atnnnn]代码)的形式写入数据,原型节点标识符充当规范节点名称,并且转向路径的基础。当需要修改相同的数据时,这些原型节点标识符使应用程序能够检索和使用原始原型,确保根据原始约束进行修改。
原型也是语义查询的基础。查询以SQL(SELECT / FROM / WHERE)和W3C XPaths(从原型中提取)的综合语言表示。
在openEHR中,原型由原型对象模型(AOM)形式化。这是原型语义的对象模型。当在内存中表示原型时(例如在启用原型的EHR“内核”中),原型将作为此模型的类的实例存在。因此,AOM是原型语义的最终陈述。
在序列化形式中,原型可以以各种方式表示。 openEHR中的规范,抽象序列化是原型定义语言(ADL)。这是一个基于Frame Logic查询的抽象语言,增加了术语。 ADL原型是保证100%无损渲染任何原型的语义,并且被设计为AOM的语法模拟。然而,其他无损和有损序列化是可能的,并且一些已经存在。出于实际目的,在某些情况下使用基于XML的序列化。一个序列化纯粹表示在dADL中,ADL对象的序列化语法将在未来可用。各种HTML,RTF和其他格式用于屏幕渲染和人工审查。
openEHR模板表示为dADL文档,其对象模型符合模板对象模型(TOM)。
原型是对象结构的可扩展形式约束定义。与对象模型类一样,它们可以是专门的,以及组合的(即聚合的)。当原型已经可用于需要建模的内容时,创建专用原型,但它缺少细节或过于笼统。例如,原型openEHR-EHR-OBSERVATION.laboratory.v1包含“标本”,“诊断服务”,任何类型的单个结果以及用于分组结果的两级结果电池的通用概念。这种原型可以(并且已经)用于表示几乎任何种类的实验室结果数据。然而,诸如openEHR-EHROBSERVATION.laboratory-glucose.v1的专业化是非常有用的,并且可以容易地基于前辈定义;在这种情况下,单个结果节点被重新定义为“血糖”。正式的专业化规则是:
这使得用任何专门原型创建的数据总是与基于父原型的查询匹配 - 换句话说,对“实验室”观察的查询将正确地检索“葡萄糖”观察。这符合包含的基本本体论原理,其说明类型B的实例也是类型A的实例,其中类型B通过语义关系“IS-A”与类型A相关。专用原型通过使用从父原型导出的标识符来指示,其具有由“ - ”字符分隔的标识符的语义部分的新的子元素。
原型之间可能的第二种关系是组合,允许大数据结构通过更小的原型的分层重用来灵活地约束。组合按照原型中的“槽”来定义。插槽是原型结构中的一个点,而不是指定内联对象类型,而是使用特殊的allowarchetype约束来指定约束同一类型的其他原型,可以在该点使用。例如,原型openEHR-EHR-SECTION.vitalsigns.v1定义了标题与生命体征相关的标题结构。它还将其属性值(即标题下的内容)定义为其项目的一些可能的观察;然而,它不是定义这些内联,而是以观察原型的约束形式指定一个原型槽,在那一点上允许。最简单的约束是关于原型标识符的正则表达式。更复杂的约束可以根据其他原型中的路径来描述(例如exists(/ some / path [at0005]))。因此,槽在该点允许或排除的可能原型方面定义了“链接点”将这限制为单个原型当然是可能的。模板用于选择在一个槽中允许的特定原型实际上将在给定情况下使用。
openEHR RM中顶层信息结构中的所有节点都是“可构建”的,这些结构中的某些节点是原型“根点”。每个顶级类型始终保证是原型根点。尽管理论上可以对整个顶级结构使用单个原型,但在大多数情况下,特别是对于COMPOSITION和PARTY,将通过上述槽机制使用多个原型的分级结构。这允许原型的组件化和可重用性。当原型的层次结构用于顶级结构时,结构内部也会有原型根点。例如,在组合物中,ENTRY实例(即,观察,评估等)几乎总是根点。 SECTION实例是根节点,如果它们是Section结构中的顶级实例;类似地对于目录结构中的FOLDER实例。其他节点(例如内部SECTION,ITEM_STRUCTURE实例)也可以是原型根点,这取决于在运行时如何将原型应用于数据。下图说明了原型和模板对数据的应用。
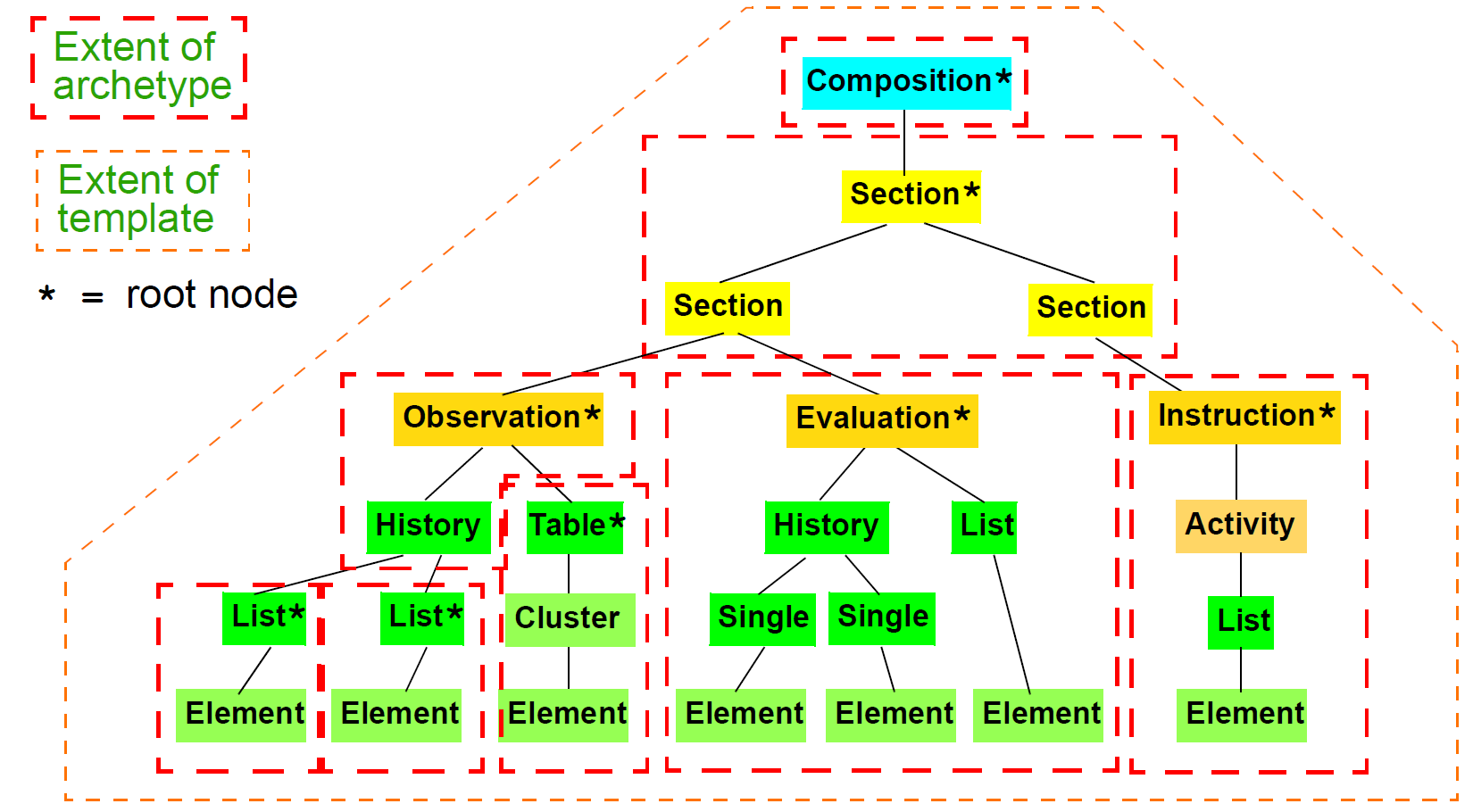
引用模型类的原型启用是通过从包common.archetyped继承类LOCATABLE(请参阅通用IM)来实现的。 LOCATABLE类包括属性archetypenodeid和archetypedetails。在数据中,前者携带原型的标识符。如果数据中的节点是根节点,则它携带生成原型的多部分标识符,并且archetypedetails携带ARCHETYPED对象,其包含与原型根点相关的信息。如果它是非根节点,则archetypenodeid属性携带生成数据节点的原型内部节点的标识符(称为“at”或“原型项”代码),并且archetype_details属性为void。
数据中的兄弟节点在某些情况下可以携带相同的archetypenodeid,因为原型提供了数据的模式,而不是精确的模板。换句话说,根据原型设计,可以在数据中复制单个原型节点。
以这种方式,openEHR数据中的每个原型化数据组成具有生成原型,其定义实例的特定配置以创建期望的合成。 “生物化学结果”的原型是一个OBSERVATION原型,并且约束OBSERVATION对象下面的实例的特定排列; “问题/ SOAP标题”原型约束形成SOAP标题结构的SECTION对象。一般来说,原型化的数据组成是从根节点开始并继续到其叶节点的数据的任何组合,在该点处,低级组合(如果存在)开始。图[archetypesanddata]中的每个原型区域及其下级原型区域是一个原型数据组成。
注意: 必须注意不要将通用术语“组成”与在组合物类中定义的openEHR和CEN EN 13606中的该词的具体使用混淆;具体使用总是通过使用术语“组合物”来指示。
使用原型在EHR(和其他系统)中创建数据的结果是,任何顶级对象中的数据结构都符合模板所选原型的组合中定义的约束,包括所有可选性,值,和术语约束。
使用openEHR原型和模板可以在openEHR体系结构中无处不在地使用路径。路径是从原型和模板中提取的,并且是使用Xpath兼容的语法从属性名称和原型节点标识符构造的,如下图所示。这些路径用于识别模板或原型中的任何节点,例如深度在“血压测量”原型内的“舒张血压”ELEMENT节点。由于原型节点标识符在运行时嵌入到数据中,原型路径可用于提取符合原型特定部分的数据节点,为查询提供非常强大的基础。路径也可以使用更复杂的谓词(仍然在Xpath样式中)构造成数据。 openEHR中的路径在第52页的路径和定位符下详细解释。
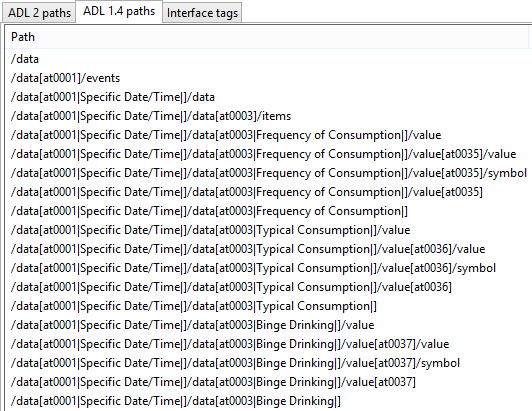
openEHR原型和模板被设计为正式的人工制品,以便在运行时是可计算的。它们执行两个关键功能。第一个是在数据捕获或导入时间方便数据验证,即保证数据不仅符合参考模型,而且符合原型本身。原型的数据验证是通过使用openEHR模板来实现的。第二个功能是作为查询的设计基础。由于数据是基于原型捕获的,所以所有openEHR数据都保证符合由模板中的原型组合创建的“语义路径”。路径(例如上面的图[archetype_paths]中所示的)被合并到熟悉的SQL风格语法中,以形成可以被评估以在语义基础上检索项的查询。
原型主要由临床或其他领域专家设计,并且经常需要对主题领域的显着研究,例如产科。开发过程可能发生在国家或国际层面,需要在实际系统中进行同行评审和测试。这符合原型的语义价值,即作为可重用的内容模型。因此,从任何给定的部署场所的观点来看,原型最可能是在别处开发的,并且驻留在公认的,质量保证的存储库中。
这样的存储库可能包含数百甚至数千个原型。然而,大多数EHR站点将仅需要相对较小的数量。临床专家估计,100个原型将照顾常规的一般实践和急性护理,包括实验室的80%,其中许多是专门化较少数量的关键原型。然而,对于给定的位点,哪100种原型是有用的,可以根据所提供的保健类型而改变。糖尿病诊所,癌症,骨科医院病房,老年护理院。一般来说,可以预期几乎所有的原型部署站点将只使用一小部分的已发布原型。一些网站也可能开发少量自己的原型;这些将是现有原型的专业化。
虽然原型是openEHR二级结构第二层中主要的共享和仔细的质量保证设计活动,但模板是更多的本地事务,并且可能是许多系统设计者与原型的联系点。模板通常基于三个事物来设计:
期望在屏幕形式或报告中;
什么原型已经可用;
本地使用术语。
模板通常将通过符合openEHR模板对象模型的工具在本地创建。
在GUI应用程序的情况下,链中的最后一步是GUI屏幕窗体。这些是以多种方式和技术创建的。在某些情况下,它们将部分或完全从模板生成。不管细节如何,屏幕形式和模板之间的连接将在工具环境中建立,使得当用户请求表格时,相关模板将被激活,从而激活相关原型。
另外的技术细节可能在许多部署情况中起作用:由于环境所需的原型和模板将被预先知道,所以它们可以从可共享的openEHR形式(即ADL,TOM文件)被编译成近运行时形式),其中它们是从存储库或本地工具接收的。此表单通常因站点而异,并且都会提高性能,并确保只有经过验证的原型和模板才会被应用程序访问。在这样的系统中,模板的运行时形式最可能包含相关原型的副本。
原型,模板和屏幕窗体的部署如下所示。
验证是原型的主要运行时函数 - 它是首先创建“基于原型的”数据,然后修改。基于原型的验证可以在GUI应用程序或数据导入服务中使用。虽然数据源(击键或接收到的XML或其他消息)不同,逻辑过程是相同的:根据输入流创建基于原型的openEHR数据。
根据实施方式和护理设置的其他方面,运行时的过程在一些细节中可以变化,但是主推力将是相同的。在特定站点使用的原型将始终在运行时通过为该站点或系统开发的openEHR模板进行调解;这些通常将链接到屏幕形式或其他形式的人工制品,以实现原型与用户或应用程序之间的连接。由于用户选择在屏幕上进行的原型,因此在运行时部分地构造模板并不罕见,尽管用户当然不会直接意识到这一点。无论如何,在根据相关原型创建和验证数据时,将完全指定执行作业的模板。
数据创建和提交的实际过程如下所示。过程的本质是“内核”组件通过维护“模板空间”和“数据空间”来执行数据创建和验证的任务。前者包含由于显示屏幕形式而检索的模板和原型;后者包含由于用户在屏幕上的活动而构造的数据结构(openEHR参考模型的实例)。当数据最终提交时,由于每次用户尝试更改数据结构时进行检查,因此它们保证符合模板/原型定义。提交的数据包含生成原型的“语义印记”,以数据的每个节点上的原型节点标识符的形式。在数据模型中的这种简单包含确保所有原型数据都可以通过使用原型路径进行查询。在XML表示中,原型节点ids表示为XML属性(即在标记内),从而使XPath能够基于这些标识符方便地导航通过数据(更多细节在下一节中)。
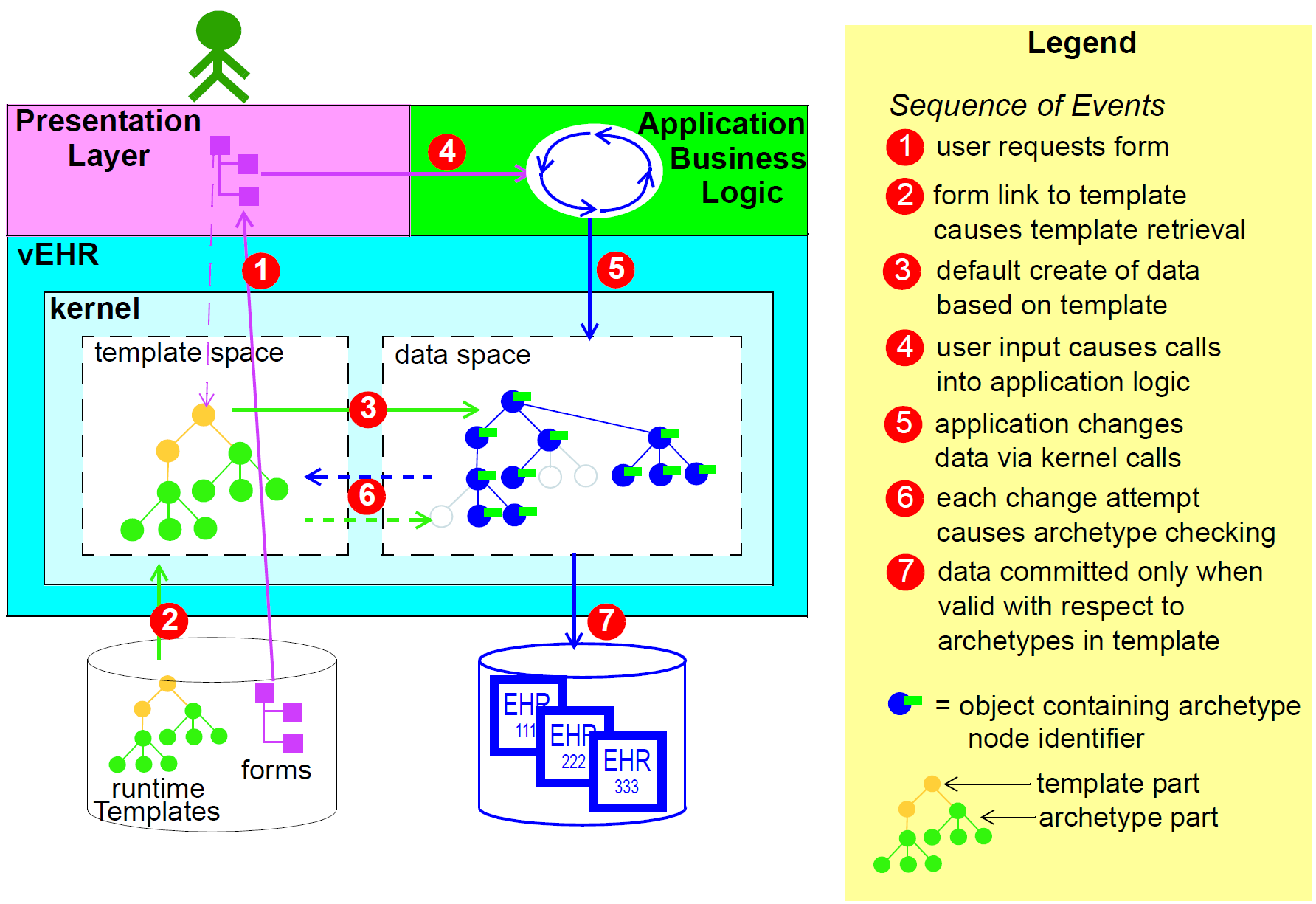
如果数据随后被修改,则它们与相关模板和原型一起被带入内核中,并且嵌入式节点标识符允许内核继续执行对数据的改变的适当检查。
原型的第二个主要计算功能是支持查询。 如上所述,在下一节中,从原型提取的路径是对数据进行查询的基础。 查询在AQL(原型查询语言)中定义,本质上是从原型提取的SQL和XPath样式路径的综合。 以下是一个示例AQL查询,意为“获取特定患者的BMI值超过30 kg / m2”:
SELECT o/[at0000]/data[at0001]/events[at0002]/data[at0003]/item[0004]/value
FROM EHR [uid=@ehrUid]
CONTAINS COMPOSITION c [openEHR-EHR-COMPOSITION.report.v1]
CONTAINS OBSERVATION o[openEHR-EHR-OBSERVATION.body_mass_index.v1]
WHERE o/[at0000]/data[at0001]/events[at0002]/data[at0003]/item[0004]/value > 30
openEHR的虚拟知识管理器(CKM)上提供了一组经过严格检查的原型。这个集合是由数以百计的临床专业人士,并不断成长。
openEHR体系结构包括路径机制,其使得能够使用“语义”(即,基于原型的)X路径兼容路径从结构的顶部指定顶级结构内的任何节点。这种路径的可用性从根本上改变了具有健康信息的可用查询可能性,并且是openEHR的主要区别特征之一。
在技术上,路径和诸如OBJECTVERSIONID的版本标识符的组合形成可以使用LOCATABLE_REF表示的“全局限定的节点引用”。它也可以在便携式URI形式中表示为DVEHRURI,称为“全局限定的节点定位符”。任何一种表示都允许从任何地方引用任何openEHR数据节点。本节介绍路径的语法和语义,以及URI的引用形式。在下文中,术语“原型路径”是指从原型提取的路径,而“数据路径”是指标识数据中的项目的路径。它们在形式上没有不同,并且这个术语仅用于指示它们在哪里使用。
openEHR中的路径在Xpath1兼容语法中定义,它是原型定义语言(ADL)中描述的路径语法的超集。该语法被设计为可以容易地映射到Xpath [Xpath]表达式,以用于基于openEHR的XML。
定位器表达式中使用的数据路径语法遵循由段组成的路径的一般模式,每个段由属性名称组成,并由斜杠('/')字符分隔,例如:
attribute_name / attribute_name / ... / attribute_name
注意: 在所有openEHR文档中,术语“属性”用于“对象的属性”的面向对象的意义,而不是出现在标签中的命名值的XML意义。这里描述的语法不应该被认为必须具有到XML实例的文本映射,而是具有到面向对象的数据结构的逻辑映射。
路径选择对象,它是路径中最终属性名称的值,从树中的某个起点和路径中给出的属性名称开始。起始点由路径的初始部分指示,并且可以通过两种方式指定:
相对路径:路径以属性名称开始,起点是树中的当前点(由某些先前的操作或知识给出);
绝对路径:路径以a开头;起点是结构的顶部。
此外,来自Xpath的//符号可用于定义路径模式:
仅使用属性名称指定的路径有两种限制。首先,它们只能在没有诸如列表或集合的容器的结构中定位对象。然而,在任何现实数据中,包括大多数openEHR数据,列表,集合和散列结构是常见的。需要额外的语法来匹配容器属性引用的兄弟之间的特定对象。它采用在段中相关属性后面的括号('[]')中的谓词表达式形式,即:
attribute_name [谓词表达式]
路径的一般形式类似于以下内容:
attribute_name / attribute_name [谓词表达式] / ...
这里,谓词表达式可选地用于在参考模型中定义为容器类型(即具有大于1的基数)的那些属性。如果未在容器属性上使用谓词表达式,则选择整个容器。注意,谓词表达式甚至在单值属性上也是可能的,并且可以使用(例如,如果通用路径处理软件不能区分差异),但不是必需的。
基本路径的第二个限制是它们不能基于其他条件定位对象,例如具有具有特定值的子节点的对象。为了解决这个问题,谓词表达式可以用于通过包括路径,运算符,值和括号的布尔表达式,基于相对于对象的其他条件来选择对象。 openEHR中使用的谓词表达式的语法是带有少量快捷方式的谓词的Xpath语法的子集。
最重要的谓词使用archetypenodeid值(继承自LOCATABLE)来限制从容器返回的项,例如限制在CLUSTER中的某些ELEMENT。快捷方式形式允许原型代码独立地包括在谓词中,例如。 [at0003]。此快捷方式对应于对运行时数据使用原型路径。典型的原型派生路径如下(应用于Observation实例):
/ data / events [at0003] / data / items [at0025] / value / magnitude
该路径指的是包含完整Apgar结果结构的观察值中的1分钟Apgar总数的大小。在此路径中,[atNNNN]谓词是标准Xpath中[@archetypenodeid ='atNNNN']的快捷方式。
注意: 而原型路径在原型中始终是唯一的,由于在容器内重复使用相同的原型节点,它可以对应于运行时数据中的多个项。
如果某些数据中的LOCATABLE.name值填充了meningful值,则可以使用name.value(在谓词中采用类似Xpath的表单名称/值)和archetypenodeid值的组合形成有用的谓词。该表达式的标准Xpath形式由以下示例:
/ data / events [@archetype_node_id ='at0001'and name / value ='standing']
其中openEHR等价于:
/ data / events [at0001 and name / value ='standing']
由于原型节点标识符和名称值的组合在原型数据库中非常常见,因此对于名称/值表达式也可以使用快捷方式,即简单地将值包含在逗号后面,如下所示:
/ data / events [at0001,'standing']
可以使用其他谓词,基于其他属性的值,如ELEMENT.name或EVENT.time。 archetypenodeid和其他此类值的组合通常用于查询,例如以下路径片段(应用于OBSERVATION实例):
/ data / events [at0007 AND time> = '24 -06-2005T09:30:00']
此路径将选择OBSERVATION.data中的事件,其archetypenodeid含义为“摘要事件”(在某些原型中为at0007),并且在给定时间或之后发生。以下示例将选择包含“其他细菌性肠道感染”(ICD10代码A04)诊断(at0002.1)的评估:
/data/items[at0002.1
AND value / define_code / terminology_id / value ='ICD10AM'
AND value / define_code / code_string ='A04']
顶层结构中的路径严格遵守参考模型相关部分中的属性和函数名称。需要谓词表达式来将路径中的各个点中的多个兄弟节点区分为这些结构,但是特别是在原型“链接”点处。链接点是一个原型从另一个接管,如图[archetypesanddata]中所示。组合中的链接点出现在组合和区域结构之间,可能在区域结构和其他子区域结构(受不同的区域原型约束)之间,以及组合或区域结构和条目之间。如果在较低级别的结构(例如Itemlists等)上使用原型设计,则链接也可能发生在条目内部。大多数链接点对应于容器类型,例如List
以下路径是引用合成中的项目的示例:
/content[openEHR-EHR-SECTION.vital_signs.v1 and name / value ='Vital signs'] / items [openEHR-EHR-OBSERVATION.heart_rate-pulse.v1 and name / value ='Pulse'] / data / events [ at0003 and name / value ='Any event'] / data / items [at1005]
/content[openEHR-EHR-SECTION.vital_signs.v1 and name / value ='Vital signs'] / items [openEHR-EHR-OBSERVATION.blood_pressure.v1 and name / value ='Blood pressure'] / data / events [at0006和name / value ='any event'] / data / items [at0004]
/content[openEHR-EHR-SECTION.vital_signs.v1,'Vital signs'] / items [openEHR-EHR-OBSERVATION.blood_pressure.v1,'Blood pressure'] / data / events [at0006,'any event'] / data / items [at0005]
其他顶级类型中的路径遵循相同的一般方法,即,通过沿着层次结构遵循所需的属性来创建。
原型路径不能保证唯一地标识数据中的项目,因为一个原型节点可以对应于数据中的多个实例。然而,能够构建到真实数据中的项目的唯一路径通常是有用的。这可以通过在路径谓词中使用除archetypenodeid之外的属性来完成。
获取数据中运行时节点的唯一路径的最可靠方法是使用UUID填充继承的LOCATABLE.uid字段。谓词可以仅由uid值或者uid值和archetypenodeid值的组合形成,尽管在技术上是冗余的,但是更有信息性(例如,它可以用对于用户可见的archetypenodeid来显示)。这是实现运行时唯一节点标识的优选方法。该表达式的标准Xpath形式由以下示例:
/ data / events [@ uid ='25f2f224-64f0-41ec-a5c7-c31c040c77ce'] <! - 假设'uid'是XSD中的XML属性 - >
/ data / events [@archetype_node_id ='at0001'and @ uid ='25f2f224-64f0-41ec-a5c7-c31c040c77ce']
其中openEHR等价于:
/ data / events [uid ='25f2f224-64f0-41ec-a5c7-c31c040c77ce']
/ data / events [at0001 and uid ='25f2f224-64f0-41ec-a5c7-c31c040c77ce']
如果已知某些数据中的LOCATABLE.name值被跨立即同胞可靠地填充有唯一值,则可以如上所述使用name/value语以形成节点的唯一标识谓词。以下面的OBSERVATION原型为例:
OBSERVATION[at0000] matches { -- blood pressure measurement
data matches {
HISTORY matches {
events {1..*} matches {
EVENT[at0006] {0..1} matches { -- any event
name matches {
DV_TEXT matches {...}
}
data matches {
ITEM_LIST[at0003] matches { -- systemic arterial BP
count matches {|>=2|}
items matches {
ELEMENT[at0004] matches { -- systolic BP
name matches {
DV_TEXT matches {...}
}
value matches {
magnitude matches {...}
}
}
ELEMENT[at0005] matches { -- diastolic BP
name matches {
DV_TEXT matches {...}
}
value matches {
magnitude matches {...}
}
}
}
}
}
}
}
}
}
}
从原型中提取的以下路径是指收缩血压幅度:
/data/events[at0006]/data/items[at0004]/value/magnitude
原型的每个节点处的代码[atnnnn]变为在数据中的每个节点中找到的archetypenodeid。
现在考虑一个OBSERVATION实例(这里用ODIN格式表示),其中使用这种原型记录了两个血压的历史:
< -- OBSERVATION - blood pressure measurement
archetype_node_id = <"openEHR-EHR-OBSERVATION.blood_pressure.v1">
name = <value = <"BP measurement">>
data = < -- HISTORY
archetype_node_id = <"at0001">
origin = <2005-12-03T09:22:00>
events = < -- List <EVENT>
[1] = < -- EVENT
archetype_node_id = <"at0006">
name = <value = <"sitting">>
time = <2005-12-03T09:22:00>
data = < -- ITEM_LIST
archetype_node_id = <"at0003">
items = < -- List<ELEMENT>
[1] = <
name = <value = <"systolic">>
archetype_node_id = <"at0004">
value = <magnitude = <120.0> ...>
>
[2] = <
name = <value = <"diastolic">>
archetype_node_id = <"at0005">
value = <magnitude = <80.0> ...>
>
>
>
>
[2] = < -- EVENT
archetype_node_id = <"at0006">
name = <value = <"standing">>
time = <2005-12-03T09:27:00>
data = < -- ITEM_LIST
archetype_node_id = <"at0003">
items = < -- List<ELEMENT>
[1] = <
name = <value = <"systolic">>
archetype_node_id = <"at0004">
value = <magnitude = <105.0> ...>
>
[2] = <
name = <value = <"diastolic">>
archetype_node_id = <"at0005">
value = <magnitude = <70.0> ...>
>
>
>
>
>
>
>
注意: 在上面的例子中,名称值被显示为好像它们都是DVTEXT,而实际上在openEHR中,它们更可能是DVCODED_TEXT实例;或者是原型允许的。这样做是为了减小示例的大小,并且对下面所示的路径没有区别。
上面提到的原型路径匹配记录中的收缩压。在许多查询情况下,这可能是意图。然而,为了唯一地匹配每个收缩压力节点,将需要创建不仅基于archetypenodeid而且基于另一属性的路径。在上面的情况中,如果已知已经在容器属性下的立即同胞集合中可靠地填充了唯一值,则可以使用名称属性。路径是使用前面描述的`name / value'谓词的openEHR快捷形式创建的,如下所示:
/ data / events [at0006,'sitting'] / data / items [at0004] / value / magnitude
/ data / events [at0006,'sitting'] / data / items [at0005] / value / magnitude
/ data / events [at0006,'standing'] / data / items [at0004] / value / magnitude
/ data / events [at0006,'standing'] / data / items [at0005] / value / magnitude
这些路径中的每一个都具有以下形式的等效Xpath:
/ data / events [@ archetype_node_id ='at0006'and name / value ='standing'] / data / items [@ archetype_node_id ='at0004'] / value / magnitude
为了实现基于LOCATABLE.name属性的唯一路径,系统必须特别地确保兄弟节点的名称的唯一性,例如。通过系统地被设置为一个或多个其他属性值的副本。例如,在EVENT对象中,name可以是time属性的字符串副本。
一般来说,兄弟节点的属性值的唯一性不是必需的,唯一保证的唯一路径是基于位置谓词的唯一路径。
如果在系统中已知在数据中的容器属性中的项的顺序总是在存储,变换等中保留,则可以使用Xpath位置参数创建保证的唯一路径。使用上述示例,可以使用以下表达式(在openEHR和Xpath中相同)来构建对于每个事件(坐立和站立测量)的收缩压和舒张压唯一的:
/ data / events [1] / data / items [1] / value / magnitude
/ data / events [1] / data / items [2] / value / magnitude
/ data / events [2] / data / items [1] / value / magnitude
/ data / events [2] / data / items [2] / value / magnitude
11.3. EHR URI
有两种广义类别的URI可以与任何资源一起使用:直接引用和查询。第一类通常由包含引用项的系统生成,并作为定义引用传递给其他系统,而第二类是以URI的形式来自请求系统的查询。
面向查询的URI在这里没有正式定义,因为期望是将使用查询服务,并且用于查询的URI格式将取决于服务的类型(例如REST URI通常基于服务的资源)。
专用类型DVEHRURI在RM data_types包内定义,以携带此处所述的URI。 DVEHRURI实例只能引用openEHR EHR中的实体(即不是某种其他类型的资源)。
以下指导原则已被用于通知EHR URI的设计。
假设一个URI“方案”(即,在[rfc_3986] URI中的“:”之前的)用于每个主要类别的数据,即EHR,人口统计等。因此,ehr方案对应于EHR内容。
这里描述的URI指的是VERSION.data中的信息项,即指对象诸如COMPOSITION或FOLDER;
通过相关的VERSIONEDOBJECT.uid(即GUID)或VERSION.uid(3部分OBJECTVERSION_ID)在URI中标识版本。
为了以URI(统一资源标识符)的形式创建对EHR中的节点的引用,需要三个元素:顶层结构中的路径,对EHR内顶层结构的引用,引用到EHR,以及对EHR系统(即仓库)的可选参考。这些可以组合以在“ehr”方案空间中形成符合以下模型的URI:
ehr:// system_id / ehr_id / top_level_structure_locator / path_inside_top_level_structure
// - - - - - - 变化 - - - - - -
ehr:// system_id / ehr_id //指特定EHR系统/服务中的EHR
ehr:/ ehr_id //指'当前'(即本地)EHR系统内的EHR
ehr:/ ehr_id / top_level_structure_locator //特定的COMPOSITION,FOLDER等
ehr:/ ehr_id / top_level_structure_locator / path_inside_top_level_structure
//特定组合物,文件夹等的子项目
toplevelstructure_locator的可能值来自类EHR的属性名称,在ehr包中可见,即组合,目录等。
这样,任何openEHR EHR中的任何对象都可以通过URI寻址。在ehr空间内,由于长期不可靠,不使用对特定服务器,主机等的URL样式引用。相反,使用EHR和/或主题的逻辑标识符,确保URI在它们所引用的资源的生存期内保持正确。 openEHR数据类型DVEHRURI被设计为携带这种形式的URI,使得能够构造用于LINK和openEHR EHR中其他地方的URI。
ehr:URI意味着在ehr空间中可用的名称解析机制,类似于DNS,其为http-,ftp-和其他众所周知的URI方案提供这样的服务。在建立这样的服务之前,可能使用处理ehr:URI的特定手段,以及更传统的http://风格引用。下面的小节描述了如何构造这两种URI。
在Ehr空间中,EHR的直接定位符是与受试者或患者标识符不同的EHR标识符(即EHR.ehr_id)。通常,“本地系统”中的副本是所需的副本,并且大多数时间可能是唯一存在的副本。在这种情况下,可以通过非限定标识符简单地标识所需的EHR,从而给出以下形式的URI:
ehr:/ 347a5490-55ee-4da9-b91a-9bba710f730e /
然而,由于对多个EHR系统中的一个对象的EHR的复制/同步,给定的EHR标识符可以存在于多于一个位置。不能保证每个这样的EHR是其他的完全相同的拷贝,因为允许部分拷贝。因此,在存在EHR副本的环境中,并且需要精确地识别需要哪个EHR实例,还需要系统标识符,给出以下形式的URI:
ehr://rmh.nhs.net/347a5490-55ee-4da9-b91a-9bba710f730e/
有两种逻辑方法来识别openEHR EHR中的顶级结构。第一个是通过所需的顶级对象的标识符(即VERSIONED_OBJECT.uid)。当URI使用对象标识符时,始终假定最新的中继版本。这导致像下面的URI:
ehr:/ 347a5490-55ee-4da9-b91a-9bba710f730e / compositions / 87284370-2D4B-4e3d-A3F3-F303D2F4F34B
ehr:/ 347a5490-55ee-4da9-b91a-9bba710f730e / directory
识别顶级结构的第二种方法是使用精确的版本标识符,其格式为object_id ::
creating_system_id :: version_tree_id。这导致像下面的URI:
ehr:/ 347a5490-55ee-4da9-b91a-9bba710f730e / compositions / 87284370-2D4B-4e3d-A3F3-F303D2F4F34B :: rmh.nhs.net :: 2
该URI标识其版本标识符为87284370-2D4B-4e3d-A3F3-F303D2F4F34B :: rmh.nhs.net :: 2的顶级项目,即由GUID标识的版本化对象的第二中继版本,在EHR处创建系统由net.nhs.rmh标识。注意,在版本标识符中提及系统并不意味着所请求的EHR在该系统处,只有在该系统处创建所寻找的顶级对象。
通过添加如前所述的路径表达式,可以构造指向openEHR EHR中最细粒度项目的URI,例如以下内容:
ehr:/ 347a5490-55ee-4da9-b91a-9bba710f730e / compositions / 87284370-2D4B-4e3d-A3F3-F303D2F4F34B / content [openEHR-EHR-SECTION.vital_signs.v1] / items [openEHR-EHR-OBSERVATION.heart_rate-pulse。 v1] / data / events [at0006,'any event'] / data / items [at0004]
还可以相对于当前EHR构造URI,在这种情况下,它们不提及EHR id,如以下示例所示:
ehr:compositions/87284370-2D4B-4e3d-A3F3-F303D2F4F34B/content[openEHR-EHR-SECTION.vital_signs.v1]/items[openEHR-EHR-OBSERVATION.blood_pressure.v1]/data/events[at0006, 'any event']/data/items[at0004]
ehr:directory
openEHR原型提供了一种强有力的方式来定义临床和相关数据的含义,并将数据连接或“绑定”到公认的术语,如LOINC,ICDx,ICPC,SNOMED-CT和许多其他用于医疗保健的术语和词汇。 openEHR中使用术语的方式如下:
参考模型中编码属性的值由“openEHR”术语定义。
每个原型包含其自己的内部术语,定义每个元素的含义。
与外部术语的绑定可以包含在原型中,允许直接映射到术语,或映射到返回特定值集合的查询。
原型绑定支持使用外部术语查询EHR。
以下部分描述这些功能。
openEHR有自己的小术语和代码集,用于在参考模型中提供多个属性的值集。代码集用于表示众所周知的国际标准化代码列表,其中代码本身具有有意义的值。 ISO 3166国家代码(“au”,“cn”,“pl”等)。六个这样的代码集由参考模型中的各种属性使用,每个类型CODEPHRASE(用于表示术语代码的openEHR类型)。对于其他编码属性,例如参考模型中的PARTICIPATION.function,openEHR术语采用术语设计中更正统的路由,并使用无意义的代码和量规定义组中的值集。这些属性总是类型DVCODEDTEXT;代码本身包含在definecode属性中。
openEHR术语在openEHR术语规范[openehrterminology]中进行了描述,在openEHR术语页[openehrterminology_resources]上提供了可计算表达式。
原型包含自己的本地术语(在原型的“本体”部分中找到)。当没有结构的术语(即没有关系)和当同义词不重要时,使用内部术语集是适当的。因此,使用限于术语的小的平面列表。除了上述计算效率之外,术语在原型内部的优点是:
查询可以单独基于原型,不需要与术语服务器交互;
术语的翻译是在明确的专题上下文(因为每个原型都是关于一个特定的主题),因此更有可能是准确的;
原型中需要的许多术语即使在非常大的术语中也不可用;
人们可以基于原型共享数据,即使他们不共享术语。
然而,很清楚,许多原型需要连接到外部术语以提供自动处理的全部好处;这将在下一节中描述。内部术语采用原型结构的每个节点的一组{代码,文本,描述}语义定义的形式。每个这样的术语由“at”(原型术语)代码来标识,例如[at0012]。在原型中本地定义的每个代码用于两个目的之一:
以语义地标识原型的数据节点(即,“命名”数据),或
以提供叶属性的值集。
例如,“Apgar结果”原型中的本地代码可以包含用于“1分钟事件”和“2分钟事件”的术语。这些代码与原型的“定义”部分中的参考模型节点相关联。在Apgar示例中,两个代码(例如[at0003]和[at0026])将映射到参考模型类型EVENT(rm.data_structures.history包)的节点,如下所示。正是这种映射是原型路径的基础:原型路径只是参考模型属性名称和节点代码的交替模式。
OBSERVATION[at0000] matches { -- Apgar score
data matches {
HISTORY[at0002] matches { -- history
events cardinality matches {1..*; unordered} matches {
POINT_EVENT[at0003] occurrences matches {0..1} matches {-- 1 minute
offset matches {|PT1M|}
data matches {
ITEM_LIST[at0001] matches {-- structure
items cardinality matches {0..1; ordered} matches {
ELEMENT[at0005] occurrences matches {0..1} matches {-- Heart r
value matches {
ORDINAL matches {
value matches {
0|[local::at0006], -- No heart beat
1|[local::at0007], -- Less than 100 bpm
2|[local::at0008] -- Greater than 100 bpm
}
}
}
}
}
}
}
}
POINT_EVENT[at0026] occurrences matches {0..1} matches {-- 2 minute
offset matches {|PT2M|}
data matches {
use_node ITEM_LIST /data[at0002]/events[at0003]/data[at0001]
...
}
}
}
}
}
}
...
第二次使用本地代码作为值。 上面,由代码[at0005]标识的ELEMENT节点具有作为其值约束的ORDINAL类型,其值可以是0,1或2.这些值中的每一个由代码[at0006],[at0007]和[at0008 ]。 显示这些术语的原型本体的提取如下所示。
ontology
primary_language = <"en">
languages_available = <"en", "en-us">
terminologies_available = <"LNC205", ...>
term_definitions = <
["en"] = <
items = <
["at0000"] = <
description = <"Clinical score derived from assessment of
breathing, colour, muscle tone, heart rate and reflex
response usually taken at 1, 5 and 10 minutes after birth">
text = <"Apgar score">
>
["at0003"] = <
description = <"Apgar score at one minute">
text = <"1 minute">
>
["at0006"] = <
description = <"No heart beat is present (palpation at base of
umbilical cord)">
text = <"No heart beat">
>
["at0007"] = <
description = <"Heart rate of less than 100 beats per minute">
text = <"Less than 100 beats per minute">
>
["at0008"] = <
description = <"Heart rate of greater than or equal to 100
beats per minute">
text = <"Greater than 100 beats per minute">
>
["at0026"] = <
description = <"Apgar score 2 minutes after birth">
text = <"2 minute">
>
>
>
>
term_bindings = <
["LNC205"] = <
items = <
["/data[at0002]/events[at0003]/data/items[at0025]"] = <[LNC205::9272-6]> -- 1 minute total
["/data[at0002]/events[at0026]/data/items[at0025]"] = <[LNC205::9271-8]> -- 2 minute total
>
>
第一种绑定是原型内部将内部代码映射到来自外部术语的代码的能力。绑定根据外部术语进行分组,允许原型中的任何给定的内部代码绑定到多个术语中的代码。通常,外部术语提供的覆盖是不完整的,并且映射可以是近似的,因此必须首先在创建映射中进行。在上面所示的例子中,分别示出了结合到1分钟和2分钟Apgar总数的LOINC代码的两个路径。在该示例中,整个路径被绑定,意味着当[at0025]发生在第一路径中时,该映射仅在[at0025]和[LNC205 :: 9272-6]之间保持;当其发生在第二路径中时,映射到不同的LOINC代码。这就是所谓的来自外部术语的“预协调”代码如何映射到openEHR原型概念。
也可以在原子内部代码和外部代码之间进行绑定,在这种情况下,无论内部代码在原型内使用多少次,映射总是成立。
关于术语的一个重要的要求是为在原型中定义的属性指定值集。有时,价值集在本原型中被定义,因为术语在公布的术语中不可用,并且由于缺少封装,在任何情况下可能太难以在其中定义。术语“无努力”,“中等努力”和“哭泣”例如是用于Apgar结果1的“呼吸”属性的识别值。在Apgar /呼吸的上下文中,含义是清楚的;然而,清楚地,在术语如SNOMED-CT内的这个术语的术语将需要预协调。更重要的是,将SNOMED术语映射为“不努力”似乎没有什么商业价值,因为包含“无努力”的项目的查询在临床上下文中不可能有用。
然而,对于许多其他类型的属性,术语是值的适当来源。通常,这些属性定义了诸如疾病和血型的现实世界现象的种类,而不是诸如“不努力”或“蓝色”的现象的质量。对于这些属性,需要与外部术语的不同类型的连接。这是以与单代码绑定类似的方式实现的:定义内部代码,在这种情况下是“ac”代码(“ac”=原型约束),并且这被绑定到对一个或多个外部术语的查询,结果将是从该术语设置的(可能是结构化的)值。逻辑方案如下图所示,其中要编码的属性值是“血型表型”。
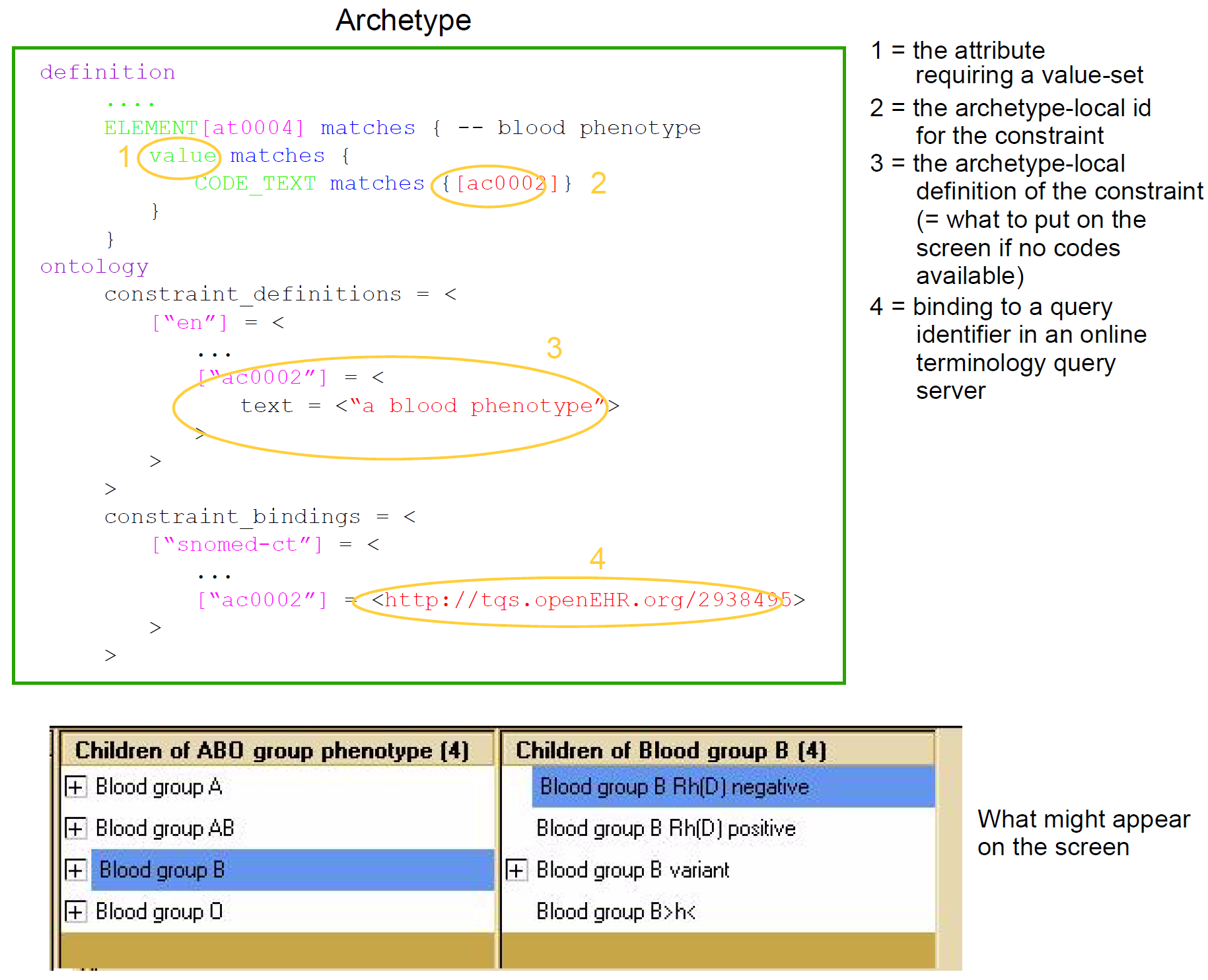
目前没有这样的查询的标准。这不直接影响原型,因为它们只保存查询的标识符;查询本身在“术语查询服务器”中定义。此查询的结果是血型表型的列表,其可能如图的底部所示archetypeconstraintbinding。
通过EHR数据的查询经常被称为关于健康信息的术语的主要效用。使用在原型中定义的映射,许多方法是可能的,然而,需要首先理解预期查询的语义。考虑对患者记录上的“腺癌”的查询。 SNOMED-CT包括以“腺癌”开始的63个术语(和171个术语,其包括作为短语的次要部分的单词),一些作为共同父母的孩子。然而,这些术语并不都有一个共同的父母;必须做出选择哪些术语对应于查询的意图。如果要找到任何以前的“腺癌”诊断,那么至少必须包括[snomed-ct | 25 |腺癌|],“...肝”的术语。这些在“临床发现”层次结构中,因此使用这些后面的术语应当确保匹配不与记录中相同术语的其它使用相关。 “对腺癌的恐惧”或“腺癌的最小风险”。这种正确匹配完全取决于软件应用和/或创建数据的用户首先正确使用SNOMED-CT术语。很容易想象一个以两个名称/值对形式保存数据(包括openEHR数据)的应用程序:<“principal diagnosis”,[snomed-ct :: 35917007 | adenocarcinoma |])>和<“site” “lung”>。使用[snomedct :: 254626006 |肺腺癌]的查询将失败,即使这正是数据的含义。数据没有错误,但是教训很清楚:查询中的数据和代码使用的编码必须由通用模型控制,否则没有可靠的处理数据的希望。
在openEHR aproach下,基于路径的查询可用于指定(例如):
基于具有在等于或被归入“临床发现”的路径/data/items[at0002.1.1]/value/code(组织学诊断)上的值的问题 - 诊断 - 组织学 - 分期原型来找到评估,到“或”包括“”腺癌“。
这里的假设是,这条路径上的值最初由采用路径的原型限制,以符合关系{is-a“临床发现”和is-a“异常形态质量”}。然后迫使肺腺癌的任何发现来自所得到的包含层级;其他“腺癌”术语不能错误地在这个位置使用。
然而,即使原型没有以这种方式限制价值,在相同路径搜索任何“腺癌”术语的相同查询可以合理地用于定位“先前的腺癌诊断”,因为这是唯一的使用原型。以类似的方式,原型基于路径的查询可以用于区分在条目和临床语句部分中描述的其他潜在的模糊性。
前面的章节描述了openEHR规范的软件结构。在这里我们描述如何将包架构应用于构建真实系统。在任何openEHR系统中的通用架构方法可以被认为是五层(即“五层”架构)。层级如下。
持久性:数据存储和检索。
后端服务:包括EHR,人口统计,术语,原型,安全性,记录位置等。在此层中,不同服务的分离是透明的,并且每个服务具有粗粒度服务接口。
虚拟EHR:此层是中间件,并且包括对提供对相关服务的访问的各种后端服务的一组连贯的API,从而允许用户访问EHR;包括EHR,人口统计,安全,术语和原型服务。它还包含原型和模板启用的内核,该组件负责创建和处理启用原型的数据。在此层中,隐藏后端服务的分离,只显示功能。其他虚拟客户端也是可能的,包括用于后端服务的其他组合的API。
应用程序逻辑:此层包含特定于应用程序的任何逻辑,可能是用户应用程序或另一个服务(如查询引擎)。
表示层:此层由应用程序的图形界面组成(如果适用)。
在大型部署中可以使用相同的层,如下图所示,或者简单地作为单机应用程序中的层。
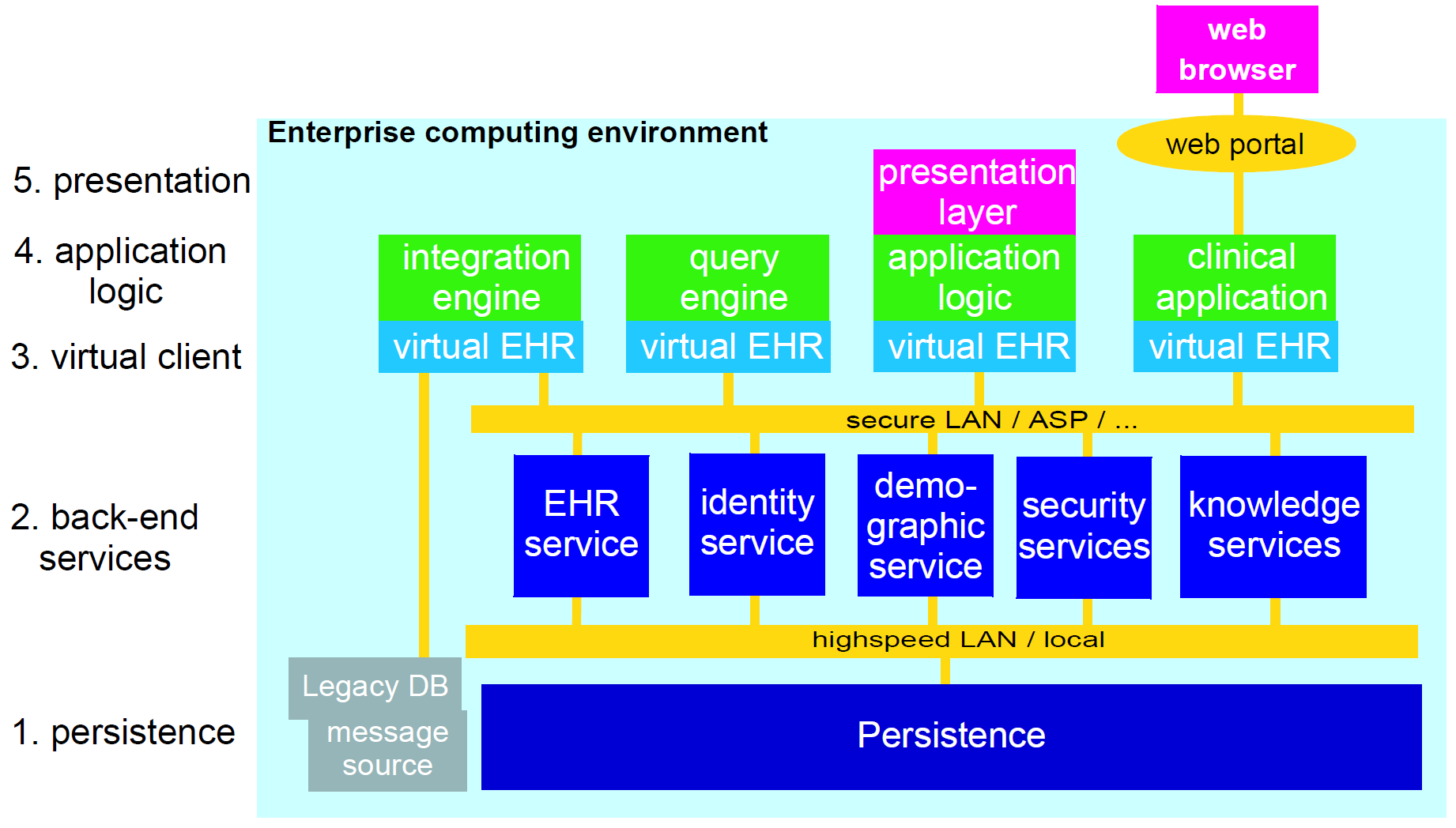
下图说明了openEHR软件架构的主要部分与5层方案的近似映射。显然,使用架构的部分将取决于各种实现选择;因此所示的映射不是确定的。然而,在大多数系统中,部分架构的主要用途可能是类似的,如下所示:
RM和AM:主要用于构造原型和模板处理内核;
RM common.change_control包:提供版本化服务(如EHR和人口统计)版本控制的逻辑;
SM:各种服务模型包定义了主要服务的暴露接口;
SM virtual_ehr包定义虚拟EHR组件的API;
原型:原型可以在一些应用中直接假定。专门的围产期可能部分基于这个专业化的原型家族;
模板:原型和模板将用于应用程序的表示层。
一些将基于GUI代码在其上,而其他人将有工具生成代码,或动态生成基于特定模板和原型的表单。将来,openEHR可能会发布抽象持久性API和优化的持久性模型(现有RM模型的转换),以帮助实现数据库。
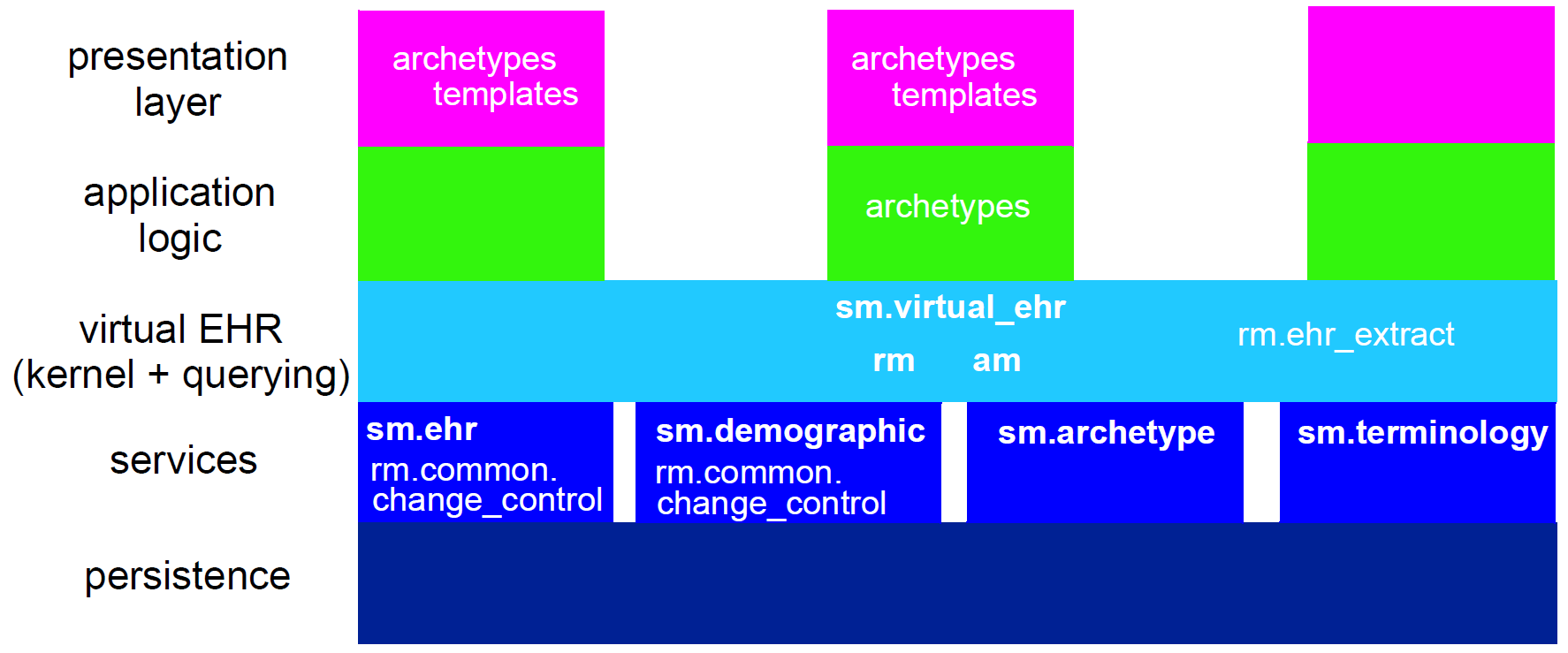
将数据输入和输出EHR是openEHR旨在满足的最基本的要求之一。在“greenfield”(新构建)情况下,并且对于由GUI应用程序通过openEHR EHR API创建的数据,没有问题,因为使用了本机openEHR结构和语义。在几乎所有其他情况下,必须考虑现有的数据源和汇。一般来说,外部或“遗留”数据(这里该术语是为了方便而使用,并且不暗示关于所讨论的系统的年龄或质量的任何数据)具有与openEHR数据不同的语法和语义格式,并且无缝转换需要解决水平。
现有的数据源和接收器包括关系数据库,HL7v2消息,HL7 CDA文档,并且可能包括CEN EN13606数据。 HL7v2消息可能是许多国家最常见的病理信息来源之一; EDIFACT消息是另一种。最近,HL7v2消息被设计用于转介,甚至排放摘要。不是所有的传统系统都是标准化的;大多数医院和GP产品都有自己的私人模型的数据和术语使用。
相对于遗留数据的主要需求是能够将来自多个相互不兼容的源的数据转换成用于每个患者的单个,标准化的以患者为中心的EHR,然后可以纵向查看和查询。这使得GP和专家笔记,诊断和计划能够与来自多个来源,患者说明,行政数据等的实验室结果集成,以提供患者旅程的连贯记录。
在技术术语中,必须处理多种类型的不兼容性。不能保证传入事务的范围和目标openEHR结构的对应关系 - 例如,传入文档可以对应于多个临床原型。结构通常不对应,遗留数据(特别是消息)通常具有比目标原型中定义的结构更平坦的结构。术语的使用在现有的系统和消息中是非常不稳定的,也必须加以处理。数据类型也不会直接对应,因此,例如,必须进行传入字符串“110/80 mmHg”和两个DV_QUANTITY对象的目标openEHR形式之间的映射,每个对象都有自己的值和单位。
集成问题的关键方法的基础是使用两种原型。到目前为止,在本文件“原型”的意思是“设计”的原型,一般是临床,人口或行政。所有这些原型的共同因素是:
它们基于参考模型的主要部分,特别是进入子类型观察,评估,指导和行动;
它们由领域专家小组有意识地设计,并集成到openEHR archteypes的现有库中;
每个可识别的健康“概念”有一个原型,例如观察类型,人类类型等。
第二类原型是“集成”原型。这些特征如下:
它们基于相同的高级类型(COMPOSITION,SECTION等),但使用Entry子类型GENERIC_ENTRY(参见EHR信息模型);
它们被设计为模仿遗留或现有数据或消息的结构;设计工作因此是完全不同的,并且更可能由熟悉输入数据的结构的IT或其他技术人员来完成;
每个消息类型有一个集成原型或可识别的源数据作为EHR的事务是有意义的。
在数据集成环境中,“设计”原型总是定义数据的目标结构,编码和其他语义,而“集成”原型提供了将外部数据映射到openEHR环境的手段。
将数据导入openEHR系统的基于集成原型的策略(如下所示)由两个步骤组成。
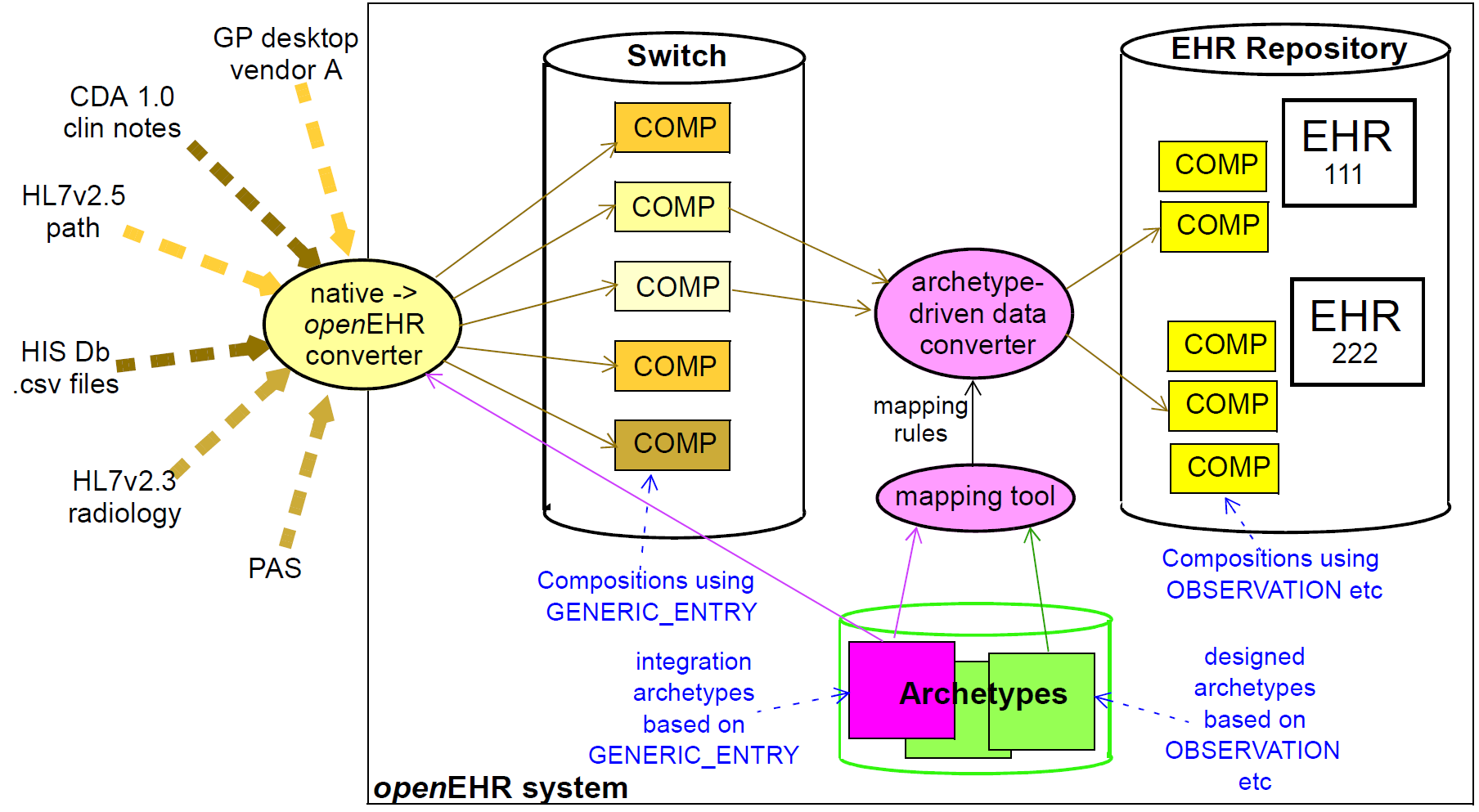
首先,数据从其原始的句法格式转换为openEHR组合/ SECTION / GENERICENTRY结构,如openEHR集成开关所示。大多数数据将出现在GENERICENTRY部分,由设计为尽可能接近地模拟传入结构(例如HL7v2实验室消息)的集成原型控制; FEEDER_AUDIT结构用于包含集成元数据。该步骤的结果是在openEHR类型系统中表示的数据(即,作为openEHR参考模型的实例),并且立即适于用正常openEHR软件处理。
在第二步中,通过使用集成和设计的原型之间的映射来实现语义变换。这种映射是由原型作者使用工具创建的。映射规则是定义结构变换,使用术语代码和其他变化的关键。当然,严重的挑战仍然在集成异构系统的业务;其中一些在馈线系统的通用IM文档部分中讨论。
openEHR规范在相关时使用可用标准,并尽可能以兼容方式。然而,对于许多标准从未以其公开的形式被验证(即,所公开的形式未在实施中测试,并且可能包含错误),openEHR进行调整以便确保openEHR模型的质量和一致性。一般来说,在openEHR中“使用”一个标准可能意味着定义一组类,将它映射到openEHR类型系统,或者包装它或以某种其他兼容的方式表达它,允许开发人员构建完全一致的openEHR系统,同时保持合规性或与标准的兼容性。与openEHR相关的标准分为以下几个类别。
这些标准定义了高级别要求或合规性标准,可用于提供openEHR与其他相关规范或系统的规范比较手段:
ISO / TR 20514.健康信息学 - 电子健康记录 - 定义,范围和上下文。 ISO TC 215 / WG 1。
ISO / TS 18308. EHR体系结构要求的技术规范。 ISO TC 215 / WG1。
以下标准影响了openEHR规范的设计:
OMG HDTF标准 - 一般设计
CEN EN 13606:2006:电子健康记录通信
CEN HISA 12967-3:健康信息服务架构 - 计算观点
以下标准主要是临床实践或概念的领域级模型,并且被用于设计openEHR原型和模板。
CEN HISA 12967-2:健康信息服务架构 - 信息观点
CEN ENV 13940:护理的连续性。
以下标准在openEHR中以细粒度级别使用或引用:
ISO 8601:表示日期和时间的语法(用于openEHR数量包)
ISO 11404:通用数据类型(映射到支持信息模型中的openEHR假设类型包)
HL7 UCUM:度量单位的统一编码(由openEHR使用数量数据类型)
HL7v3 GTS:通用时序规范语法(由openEHR时间规范数据类型使用)。
一些HL7v3域词汇映射到openEHR术语。
IETF RFC 2440 - openPGP。
以下标准正在使用中,需要进行数据转换才能与openEHR配合使用:
CEN EN 13606:2005:电子健康记录通信 - 近直接转换可能,因为openEHR和CEN EN 13606被积极维持以兼容。
HL7v3 CDA:临床文档架构(CDA)2.0版 - 可以进行相当接近的转换。
HL7v3消息。由于HL7v3消息传递规范中的流量和消息模式的多样性,目前未知的转换质量。
HL7v2消息。导入HL7v2消息数据在技术上并不困难,并且已经在一些openEHR系统中使用。也可以从openEHR导出。
openEHR中使用或引用了以下标准:
ISO RM / ODP
OMG UML 2.0
W3C XML模式1.0
W3C Xpath 1.0
ITS是通过应用从抽象模型的“全强度”语义到特定技术中的等价物的变换规则而创建的。转换规则通常包括以下映射:
类和属性的名称;
属性和函数签名映射;
基本类型的映射字符串,数字;
如何处理多重继承;
如何处理通用(模板)类型;
如何处理协变和逆变重定义语义;
具有签名xxxx:T(即,没有参数的属性)到存储的属性(xxxx:T)或函数(xxxx():T)的映射属性的选择;
如何表达前提条件,后置条件和类不变式;
假定类型之间的映射,例如List <>,Set <>和内置类型。
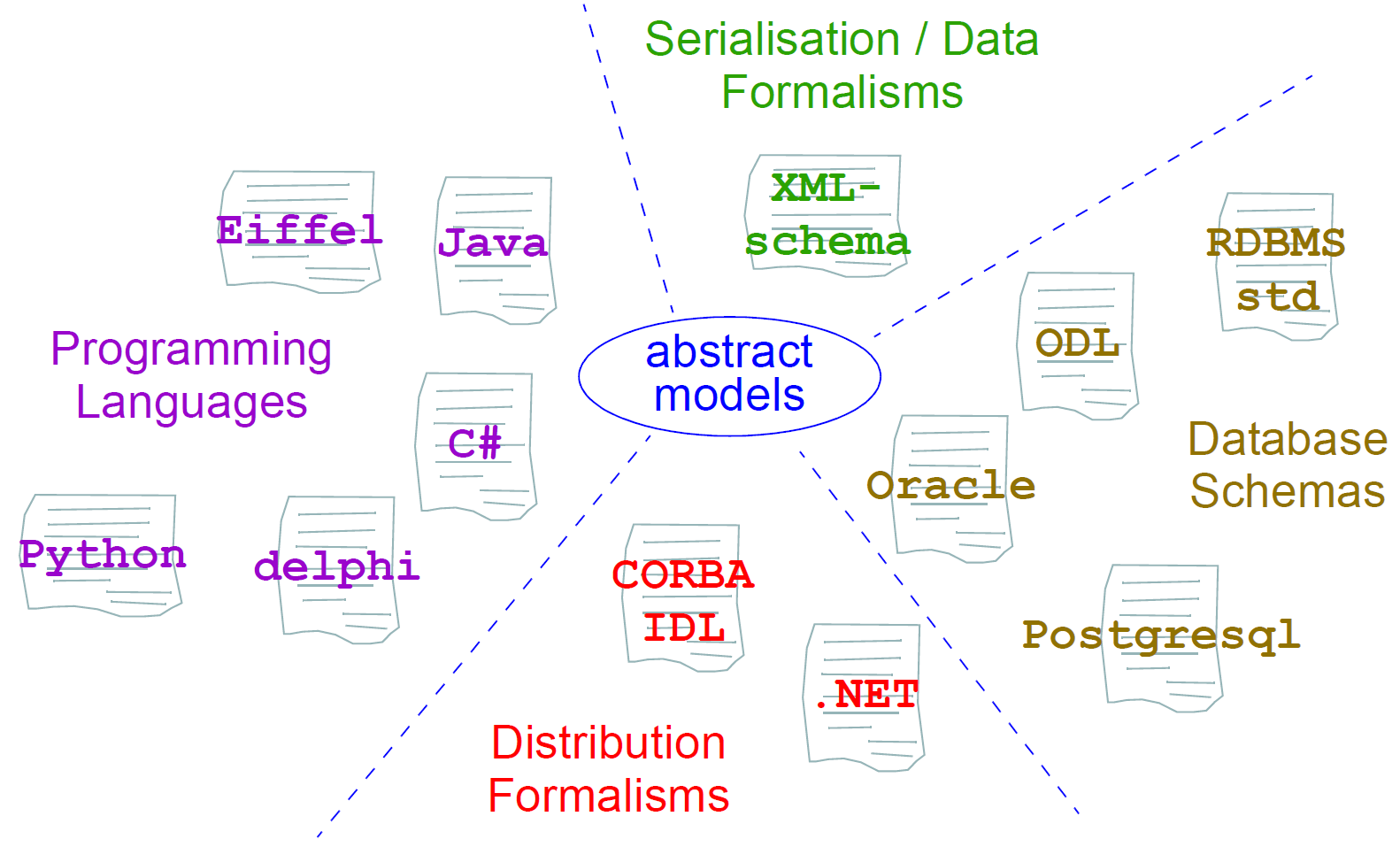
正在为一些主要的实施技术开发ITS,如下所概述。在继续之前,实施者应该总是寻找所讨论的技术的ITS。如果不存在,则需要进行定义。正在开发这样做的方法。下图说明了实现技术规范空间。每个规范记录了来自openEHR抽象模型中使用的标准面向对象语义的映射,并且还提供了ITS形式的每个抽象模型的表达式。
[Anderson_1996]罗斯·安德森。临床信息系统的安全性。可在http://www.cl.cam.ac.uk/users/rja14/policy11/policy11.html获取。
[Baretto2005] Barretto S A.设计基于指南的工作流程 - 综合电子健康记录。南澳大学博士论文。可在http://www.cis.unisa.edu.au/~cissab/BarrettoPhD_ThesisRevisedFINAL.pdf。
[Beale2000] Beale T. Archetypes:Constraint-based Domain Models for Future-proof Information Systems。 2000.可查阅http://www.openehr.org/files/resources/publications/archetypes/archetypesbealeweb2000.pdf。
[Beale2002] Beale T.Archetypes:Constraint-based Domain Models for Future-proof Information Systems。第十一届OOPSLA行为语义研讨会:为客户服务(西雅图,美国华盛顿,2002年11月4日)。由Kenneth Baclawski和Haim Kilov编辑。 Northeastern University,Boston,2002,pp。16-32。请访问http://www.openehr.org/files/resources/publications/archetypes/archetypesbealeoopsla2002.pdf。
[BealeHeard2007] Beale T,Heard S. An Ontology-based Model of Clinical Information。 2007.pp760-764 Proceedings MedInfo 2007,K.Kuhn et al。 (Eds),IOS Publishing 2007.见http://www.openehr.org/publications/health_ict/MedInfo2007-BealeHeard.pdf。
[Booch_1994] Booch G.面向对象的分析和设计与应用。第2版。本杰明/ Cummings 1994。
[Browne2005] Browne E D.工作流建模协调的健康护理提供者护理计划。南澳大学博士论文。请访问http://www.openehr.org/publications/workflow/tbrownethesisabstract.htm。
[Cimino_1997] Cimino J J. Desiderata for Controlled Medical vocabularies in the Twenty-First Century。 IMIA WG6 Conference,Jacksonville,Florida,Jan 19-22,1997。
[埃菲尔]迈耶B.埃菲尔的语言(第二版)。 Prentice Hall,1992。
[Elstein_1987] Elstein AS,Shulman LS,Sprafka SA。医学问题解决:临床推理的分析。剑桥,MA:哈佛大学出版社1987。
[ElsteinSchwarz2002] Elstein AS,Schwarz A.临床诊断的证据基础:临床问题解决和诊断决策:对认知文献的选择性审查。 BMJ 2002; 324; 729-732。
[Fowler_1997] Fowler M.分析模式:可重用对象模型。 Addison Wesley 1997
[FowlerScott2000] Fowler M,Scott K.UML Distilled(第2版)。 Addison Wesley Longman 2000。
[Grayreuter1993] Gray J,Reuter A. Transaction Processing Concepts and Techniques。 Morgan Kaufmann 1993。
[Hein_2002] Hein J L.Discrete Structures,Logic and Computability(2nd Ed)。琼斯和巴特利特2002。
[Hnìtynka_2004]HnìtynkaP,PlášilF. MOF的分布式版本控制模型。 Proceedings of WISICT 2004,Cancun,Mexico,A volume in the ACM international conference proceedings series,published by Computer Science Press,Trinity College Dublin Ireland,2004。
[Ingram_1995] Ingram D.欧洲良好健康记录项目。 Laires,Laderia Christensen,Eds。健康在新的通信时代。阿姆斯特丹:IOS出版社; 1995; pp。66-74。
[KiferLausenWu_1995] Kifer M,Lausen G,Wu J. Logical Foundations of Object-Oriented and FrameBased Languages。 JACM 1995年5月。见见ftp://ftp.cs.sunysb.edu/pub/TechReports/kifer/flogic.pdf。
[Kilov_1994] Kilov H,Ross J.信息建模 - 一种面向对象的方法。 Prentice Hall 1994。
[Maier_2000] Maier M.系统建模原则。技术报告,阿拉巴马大学在亨茨维尔。 2000.可在http://www.infoed.com/Open/PAPERS/systems.htm获得
[Martin] Martin P. UML,OWL,KIF和WebKB-2语言之间的翻译(For-Taxonomy,Frame-CG,Formalized English)。 May / June 2003. Available at http://www.webkb.org/doc/model/comparisons.html as at Aug 2004。
[Meyer_OOSC2] Meyer B. Object-oriented Software Construction,2nd Ed。 Prentice Hall 1997
[Müller2003]MüllerR. Event-oriented Dnamic Adaptation of Workflows:Model,Architecture,and Implementation。莱比锡大学博士论文。请访问http://www.openehr.org/publications/workflow/tmuellerthesisabstract.htm。
[Object_Z] Smith G.对象Z规范语言。 Kluwer Academic Publishers 2000.见http://www.itee.uq.edu.au/~smith/objectz.html。
[Rector_1994] Rector A L,Nowlan W A,Kay S. Foundations for an Electronic Medical Record。 The IMIA Yearbook of Medical Informatics 1992(Eds.van Bemmel J,McRay A)。 Stuttgart Schattauer 1994。
[Rector] Rector A L.临床术语:为什么这么难?方法。 1999 Dec; 38(4-5):239-52。可在http://www.cs.man.ac.uk/~rector/papers/Why-is-terminology-hard-single-r2.pdf。
[Richards_1998] Richards E G. Mapping Time - The Calendar and its History。牛津大学出版社1998。
[Sowa_2000] Sowa J F.知识表示:逻辑,哲学和计算基础。 2000年
[bfo]正式本体和医学信息科学研究所(IFOMIS)。基本正式本体论(BFO)。 http://ifomis.uni-saarland.de/bfo/。
[FMA] http://sig.biostr.washington.edu/projects/fm/。
[Horrocks_owl] Patel-Schneider P,Horrocks I,Hayes P. OWL Web本体语言语义和抽象语法。请参阅http://w3c.org/TR/owl-semantics/。
信息工件本体。 https://code.google.com/p/information-artifact-ontology/。
[OBO] The Open Biological and Biomedical Ontologies。见http://www.obofoundry.org/。
[OGMS]一般医学科学本体(OGMS)。 https://code.google.com/p/ogms/。
[ENV_13606-1] ENV 13606-1 - 电子医疗记录通信 - 第1部分:扩展架构。 CEN / TC 251健康信息技术委员会。
[ENV_13606-2] ENV 13606-2 - 电子医疗记录通信 - 第2部分:域名术语列表。 CEN / TC 251健康信息技术委员会。
[ENV_13606-3] ENV 13606-3 - 电子医疗记录通信 - 第3部分:分发规则。 CEN / TC 251健康信息技术委员会。
[ENV_13606-4] ENV 13606-4 - 电子医疗记录通信标准第4部分:信息交换的信息。 CEN / TC 251健康信息技术委员会。
[Corbamed_PIDS]对象管理组。人身份识别服务。 1999年3月。
[Corbamed_LQS]对象管理组。词典查询服务。 1999年3月。
[HL7v3_ballot2] JL7国际。 HL7版本3第二选票规格。可在http://www.hl7.org获得。
[HL7v3datatypes] Schadow G,Biron P. HL7版本3可交付:版本3数据类型。 (2002年第二版投票)。
[hl7v3rim] HL7。 HL7 v3 RIM。见http://www.hl7.org。
[ICD10AM]。世卫组织/ ACCD。国际疾病分类,第10次修订,澳大利亚修改。请参见https://www.accd.net.au/Icd10.aspx
[IHTSDO]国际健康术语标准制定组织(IHTSDO)。 http://www.ihtsdo.org。
[IHTSDOURIs] IHTSDO。 SNOMED CT URI标准。 http://ihtsdo.org/fileadmin/userupload/doc/download/docUriStandardCurrent-en-USINT20140527.pdf?ok。
[NLMUMLlist]国家医学图书馆。 UMLS术语表。 http://www.nlm.nih.gov/research/umls/metaa1.html。
[SNOMED_CT] IHTSDO。系统化命名医学。请参见http://www.ohtsdo.org。
[WHO_ICD]世界卫生组织(WHO)。国际疾病分类(ICD)。见:http://www.who.int/classifications/icd/en/。
[ISO_18308] Schloeffel P.(编辑)。电子健康记录参考架构的要求。 (ISO TC 215 / SC N; ISO / WD 18308)。国际标准组织,澳大利亚,2002年。
[ISO20514] ISO。综合护理EHR。见http://www.iso.org/iso/isocatalogue/cataloguetc/cataloguedetail.htm?csnumber=39525。
[UCUM] Schadow G,McDonald C J.The Unified Code for Units of Measure,Version 1.4 2000.Regenstrief Institute for Health Care,Indianapolis。请参阅http://aurora.rg.iupui.edu/UCUM
[CIMI]临床信息建模倡议(CIMI)项目。参见http://opencimi.org。
[EHCRsupA14] Dixon R,Grubb P A,Lloyd D,and Kalra D. Consolidated List of Requirements。 EHCR支持行动交付1.4。欧洲委员会DGXIII,布鲁塞尔; 2001年5月59pp可从http://www.chime.ucl.ac.uk/HealthI/EHCR-SupA/del1-4v1_3.PDF获得。
[EHCRsupA35] Dixon R,Grubb P,Lloyd D. EHCR支持行动交付3.5:“对CEN未来工作的最终建议”。 2000年10月。见http://www.chime.ucl.ac.uk/HealthI/EHCRSupA/documents.htm。
[EHCRsupA24] Dixon R,Grubb P,Lloyd D. EHCR支持行动2.4“CEN EHCRA解释和实施指南”。 2000年10月。见http://www.chime.ucl.ac.uk/HealthI/EHCR-SupA/documents.htm。
[Lloyd D,et al。 EHCR支持行动交付3.1和3.2“CEN的中期报告”。 July 1998. Available at http://www.chime.ucl.ac.uk/HealthI/EHCR-SupA/documents.htm。
[GEHRdel4]可交付成果4:GEHR临床综合性要求。 GEHR项目1992
[GEHRdel7]可交付成果7:临床功能规范。 GEHR项目1993
[GEHRdel8]可交付成果8:GEHR架构和系统的伦理和法律要求。 1994年GEHR项目
[GEHRdel192024]交付成果19,20,24:GEHR架构。 GEHR项目30/6/1995
[GeHRAUS] Heard S,Beale T.The Good Electronic Health Record(GeHR)(Australia)。请参阅http://www.openehr.org/resources/relatedprojects#gehraus。
[GeHRAusgpcg] Heard S. GEHR Project Australia,GPCG Trial。可在http://www.gehr.org/gpcg/ehra.htm。
[GeHRAusreq] Beale T,Heard S.GEHR技术要求。请参阅http://www.gehr.org/technical/requirements/gehr_requirements.html。
[SynapsesreqA] Kalra D.(Editor)。突触用户需求和功能规范(A部分)。欧盟远程信息处理应用程序,布鲁塞尔; 1996;突触项目:可交付用户1.1.1a。 6章,176页。
[SynapsesreqB] Grimson W.和Groth T.(Editors)。突触用户需求和功能规范(B部分)。欧盟远程信息处理应用程序,布鲁塞尔; 1996;突触项目:可交付用户1.1.1b。
[Synapses_odp] Kalra D.(编辑)。突触ODP信息观点。欧盟远程信息处理应用程序,布鲁塞尔; 1998;突触项目:最终交付。 10章,64页。
[synex]伦敦大学学院。 SynEx项目。 http://www.chime.ucl.ac.uk/HealthI/SynEx/。
[OCL]对象约束语言2.0。对象管理组(OMG)。可在http://www.omg.org/cgi-bin/doc?ptc/2003-10-14。
[IANA] IANA。 http://www.iana.org/。
[IEEE_828] IEEE。 IEEE 828-2005:软件配置管理计划标准。
[ISO_8601] ISO 8601标准描述了表示时间,日期和持续时间的格式。参见例如http://www.mcs.vuw.ac.nz/technical/software/SGML/doc/iso8601/ISO8601.html和http://www.cl.cam.ac.uk/~mgk25/iso-time.html 。
[ISO_2788] ISO。 ISO 2788单语词典的建立和发展指南。
[ISO_5964] ISO。 ISO 5964建立和开发多语言词典的指南。
[Perl_regex] Perl.org。 Perl正则表达式。可在http://perldoc.perl.org/perlre.html。
斯坦福大学。参见http://protege.stanford.edu/。
[rfc_2396] Berners-Lee T.Universal Resource Identifiers in WWW。可在http://www.ietf.org/rfc/rfc2396.txt。这是一个用于全局资源识别的万维网RFC。在当前在网上使用时,由Mosaic,Netscape和类似工具。有关URI的起点,请参阅http://www.w3.org/Addressing。
[rfc_2440] RFC 2440:OpenPGP消息格式。见http://www.ietf.org/rfc/rfc2440.txt和http://www.ietf.org/internet-drafts/draft-ietf-openpgp-rfc2440bis-18.txt
[rfc_3986] RFC 3986:统一资源标识符(URI):通用语法。 IETF。参见http://www.ietf.org/rfc/rfc3986.txt。
[rfc_4122] RFC 4122:通用唯一标识符(UUID)URN命名空间。 IETF。参见http://www.ietf.org/rfc/rfc4122.txt。
[rfc_2781] IETF。 RFC 2781:UTF-16,ISO 10646的编码见http://tools.ietf.org/html/rfc2781。
[rfc_5646] IETF。 RFC 5646. Available at http://tools.ietf.org/html/rfc5646。
[sem_ver]语义版本化。 http://semver.org。
[Xpath] W3C Xpath 1.0规范。 1999.可在http://www.w3.org/TR/xpath。
[uri_syntax]统一资源标识符(URI):通用语法,因特网提议的标准。 2005年1月。见http://www.ietf.org/rfc/rfc3986.txt。
[w3c_owl] W3C。 OWL - Web本体语言。请参阅http://www.w3.org/TR/2003/CR-owl-ref-20030818/。
[w3c_xpath] W3C。 XML路径语言。请参阅http://w3c.org/TR/xpath。
[openehr18308] openEHR基金会。 openEHR架构符合ISO TS 18308“EHR体系结构的要求”。请参阅http://www.openehr.org/releases/trunk/architecture/iso18308conformance.pdf。
[openEHRADLworkbench] openEHR基金会。 openEHR ADL工作台。 http://www.openehr.org/downloads/ADLworkbench/home。
[openehramoverview] openEHR基金会。 openEHR原型技术概述。请参阅http://www.openehr.org/releases/AM/latest/Overview.html。
[openehramadl14] openEHR基金会。原型定义语言1.4(ADL1.4)。请访问http://www.openehr.org/releases/AM/latest/ADL1.4.html。
[openehramaom14] openEHR基金会。原型对象模型1.4(AOM1.4)。请访问http://www.openehr.org/releases/AM/latest/AOM1.4.html。
[openehramadl2] openEHR基金会。原型定义语言2(ADL2)。请访问http://www.openehr.org/releases/AM/latest/ADL2.html。
[openehramaom2] openEHR基金会。原型对象模型2(AOM2)。请访问http://www.openehr.org/releases/AM/latest/AOM2.html。
[openehramidentification] openEHR基金会。原型标识规范。请访问http://www.openehr.org/releases/AM/latest/Identification.html。
[openehramdefpri] openEHR基金会。原型定义和原则。 (已弃用)可查阅http://www.openehr.org/releases/1.0.2/architecture/am/archetypeprinciples.pdf。
[openehramsys] openEHR基金会。原型系统。 (已弃用)可查阅http://www.openehr.org/releases/1.0.2/architecture/am/archetype_system.pdf。
[openehramoap] openEHR基金会。 openEHR原型配置文件。 http://www.openehr.org/releases/1.0.2/architecture/am/openehrarchetypeprofile.pdf。
[openehr_CKM] openEHR临床知识经理(CKM)。请参阅http://www.openEHR.org/ckm
[openehr_odin] openEHR基金会。对象数据实例符号(ODIN)。请访问http://www.openehr.org/releases/BASE/Release-1.0.3/odin.html。
[openeneHoverview] openEHR基金会。 openEHR架构概述。请参阅http://www.openehr.org/releases/BASE/Release-1.0.3/architectureoverview.html。
[openehrqueryaql] openEHR基金会。 openEHR原型查询语言(AQL)。请参阅http://www.openehr.org/releases/QUERY/latest/AQL.html。
[openehrrmdatatypes] openEHR。数据类型信息模型。请参阅http://www.openehr.org/releases/RM/latest/datatypes.html。
[openehrrmdatastructures] openEHR。数据结构信息模型。请参阅http://www.openehr.org/releases/RM/latest/datastructures.html。
[openehrrmcommon] openEHR。公共信息模型。请参阅http://www.openehr.org/releases/RM/latest/common.html。
[openehrrmehr] openEHR基金会。 EHR信息模型。 http://www.openehr.org/releases/RM/latest/ehr.html。
[openehrrmehrextract] openEHR基金会。 EHR Extrct信息模型。 http://www.openehr.org/releases/RM/latest/ehrextract.html。
[openehrrmintegration] openEHR基金会。集成信息模型。 http://www.openehr.org/releases/RM/latest/integration.html。
[openehrrmsupport] openEHR。支持信息模型。请参阅http://www.openehr.org/releases/RM/latest/support.html。
openEHR基金会。 openEHR术语http://www.openehr.org/releases/TERM/{term_release}/SupportTerminology.html。
[openeneHL基金会]。 openEHR术语项目(GitHub)https://github.com/openEHR/terminology。
最后更新2015-12-10 13:21:27 GMT