![]()
发行人:openEHR规范程序
发布:Release-2.0.6
状态:TRIAL
修订:[latest_issue]
日期:[latestissuedate]
关键词:原型,鉴定,治理
©2014 - 2017 openEHR基金会
openEHR基金会是一个独立的非营利社区组织,通过开源,基于标准的实施,促进消费者和临床医生共享健康记录。
许可:
 Creative Commons Attribution-NoDerivs 3.0 Unported。
Creative Commons Attribution-NoDerivs 3.0 Unported。 支持:
本文件所报告的工作由下列组织提供资金:
“Microsoft”和“.Net”是Microsoft Corporation的商标
'openEHR'是openEHR基金会的注册商标
“SNOMED CT”是IHTSDO的注册商标
原型是向信息模型添加领域语义的一种方法,同时避免后者的无限增长和维护,如果使用教科书方法来建模。
为了区分领域语义和信息模型具体,我们可以考虑电子卫生领域作为例子。诸如来自openEHR,ISO_13606-1,HL7 CDA等的发布的信息模型使用多级方法,其中主信息模型与表达领域语义的另一层模型分离。信息模型通常定义以下内容:
“临床数据类型”,例如。数量(单位,精度等),编码文本,有序(整数/符号连接);
各种通用临床数据结构,例如“临床表述”(由openEHR和ISO 13606-1中的类型Entry表示),“临床文献”,“报告”等;
各种基础设施类型与识别,版本控制等。
这样的信息模型可以包含50-100个类,包括用于临床数据类型的30+个类,并且能够构建对应于例如临床数据类型的各个部分和部分的实例结构。临床会诊记录或医院出院摘要。
然而,这种大小的类模型和标准UML的能力都不能自然地适应可以构成在每个特定情况下创建的临床文档的实例的可能值的数量或多样性(例如,访问专家的特定类型的患者),也不是成千上万的临床观察(例如,“收缩压”,“视力”等,其中许多由特定结构中的多个数据点组成),也不是O(1E4)实验室测试结果分析物类型。此外,在数据的名称/值表示中注释数据项(名称和值)所需的术语的大小在O(1E5)-O(1E6)概念范围内,如SNOMED CT ,ICDx和几十个其他临床术语。
上述情况适用于大多数信息丰富的行业,虽然数量不尽相同但通常非常大。
尽管技术上这些许多可能的值可以被理解为在数据创建的情况下“发生”的特定值,但是在主流IT中广泛认识到域数据值“复合体”(数据的共现结构)对应于到构成结构内值的可能组合的天文数量的一小部分的有意义模式。因此,虽然几十到几十万的“临床陈述”模式将充分地覆盖几乎所有的一般医学数据记录(即,留下终端真实世界值,例如在他们各自的健康范围内的实际血压开放),信息模型在典型使用中实际上将允许以1E10和更高的范围的顺序编号的可能的实例结构 - 定义具有1E20可能实例的类模型是相对微不足道的事情。换句话说,来自典型信息模型的大多数可能的实例数据结构是垃圾。
这类似于自然语言的情况,其中有意义的句子构成了可能的一小部分,语法正确的单词序列。

在上图中,“有意义的实例空间”(在aqua中显示)对应于任何信息系统中的感兴趣的实际数据,然而根据经典教科书方法对其进行建模的唯一方法是简单地通过增长信息模型。问题是信息模型通常是可部署软件的基础,也是数据库模式,因此常数变化意味着系统不稳定性。
众所周知,需要其他机制来实现“有意义的实例空间”的某种“模板化”,以使得能够定义共同的模式。这样做可以帮助软件或其他人工制品(通常是UI形式)的后续开发基于实际已知发生的实例结构。在Martin Fowler的1997年的书“分析模式”Fowler_1997中描述了一般需求,其中“模式”在UML图的“线上”部分中示出,但是已经知道了几十年。通常理解,这种建模不能简单地是现有软件或数据库模式的扩展。显而易见的IT原因是这样做意味着无休止的维护和更新部署的软件,更糟糕的是,频繁的数据库迁移。在运行24x365的系统中,每年定期创建千兆字节的数据,这不是一种可接受的方法。
然而,有一个可以更重要的理由是提供一种通用的方法来建模领域信息模式:域级定义或模型的作者不是软件或数据库开发者,而是某种领域专家,例如。医生或航空工程师。后一种专业人员通常不会知道或关心IT人员使用的编程或建模语言,并且通常有自己的形式主义,IT专业人员难以理解。此外,它们在其领域中使用的语义通常不能在UML或ER模型的相对简单的形式主义中直接表示。
因此,健康和其他域中的一些大型软件产品具有配置或模板构建工具,其能够建模典型的域内容模式,通常作为屏幕形式定义。这部分地解决了这两个问题:一些域语义现在与软件分离,并且它们可以由非IT人员使用专用工具来构建。

这种方法当然有许多限制:它不会对所有的“有意义的实例空间”建模,它通常与用户界面细节相关;它不会停止无意义数据实例的创建。
然而,所有主流IT的主要问题是,没有这样的建模能力是独立于特定供应商产品及其视觉形式可用的。理想地,可以以标准方式对所有域进行这种建模,即建模域模式将像UML或ER建模一样通用。不幸的是,即使是最先进的工具,可能在技术上足够强大到足以做这项工作被埋在特定的产品,并绑定到相应的专有数据模型。
一个重要的经济因素是,创建高质量领域模型是耗时和昂贵的,依赖于领域专家 - 通常是有经验的临床医生,工程师等 - 而不是IT人员。如果在特定产品(例如特定医院信息系统)内创建模型,并且该产品被替换,则通常工作人员很少食欲或可用性来重新创建在创建用于第一产品的模型/模板时完成的工作,新产品环境。在产品,网站和整个行业垂直方面,乘数,缺乏标准的方式来表示域内容的模型已成为高质量信息系统生产的重大障碍。相反,随着每个解决方案被替换,其域模型通常与它一起死。
因此,对于有效,正式,以及产品和实现与格式无关的领域建模能力的需求是清楚的。在健康中,需要形式化的域语义的绝对数量使得经典的单模型方法和简单的屏幕模板不可扩展,其他方法不得不被开发。在openEHR中,这采用原型形式主义的形式,与包括SNOMED CT,LOINC,ICDx和许多其他术语的术语结合使用。
可以区分两类域内容模型,响应于能够表示“数据点”和“数据组”的使用独立定义的普遍需要以及“数据集”的依赖于用例的定义。考虑记录患者生命体征的情况。假设可以为“血压”,“心率”和“血氧”定义内容模型。这些定义需要独立于特定用途,例如患者家庭测量,GP相遇和医院床边测量,因为在所有这些情况下,每个生命体征以完全相同的方式记录。然而,在每种情况下,这些生命体征数据点被记录在对应于发生的健康系统事件的更大的数据集中,例如GP患者健康检查或ED初始评估。
因此,存在域建模形式主义的两个相关要求:能够建模可重用域数据项和结构,其次,能够对这些通用元素的更大使用情况特定组合进行建模。替代方法是为每个数据集创建一个域模型,并在这些模型中的许多模型中重复定义循环内容的相同子模型,例如“血压”。
openEHR原型形式主义被设计为独立于任何特定的信息模型,产品,技术格式或行业垂直。它被设计成使得形式主义的实例(被称为原型)能够被计算地处理成对应于特定技术环境的期望的输出形式。这通常在openEHR工具环境中执行。
形式主义主要解决可能的数据实例结构的模型的表达,而不是诸如工作流,临床指南(其是决策图)等的更高层概念的表达,尽管其一般方法可以应用于这些中的任何一个,一个“什么可以说”的模型和一种形式主义或机制来约束有意义的子集的可能性。
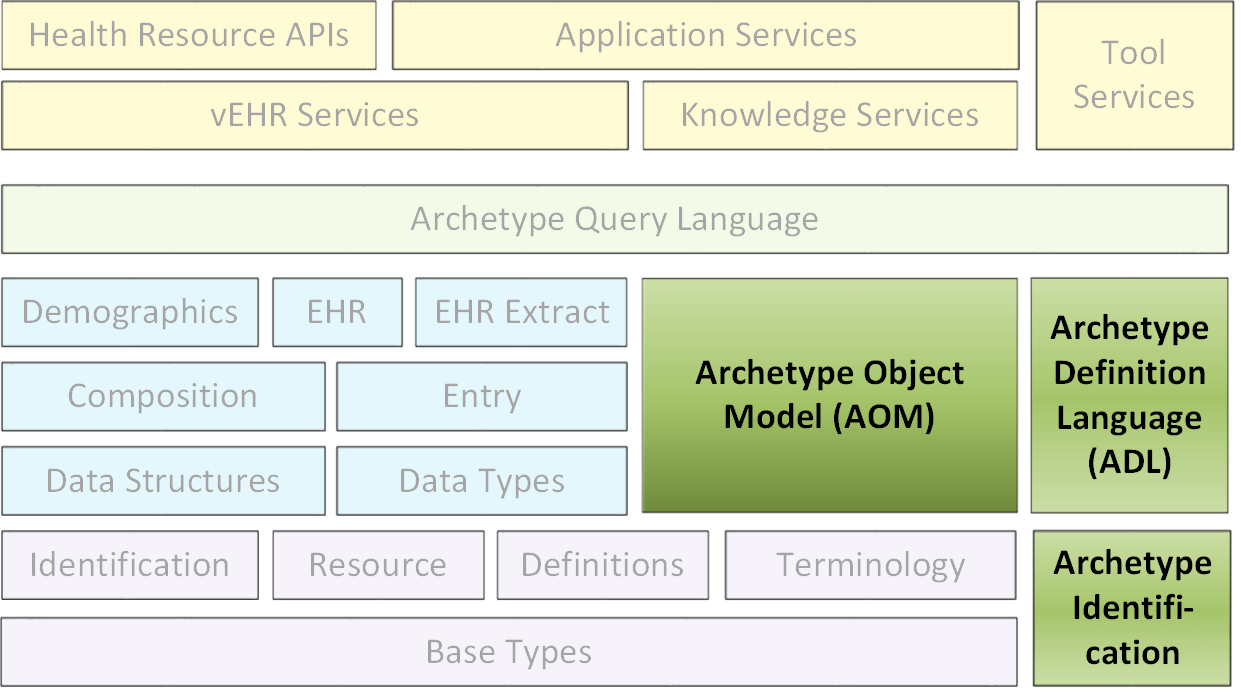
给定上述两种类型的模型,原型形式主义与正统信息模型(通常面向对象)结合,导致以下三种逻辑层中的任何领域的信息建模:
从信息模型级别分离原型和模板可以如下所示。

在此方案中,信息模型(参考模型)级别被有意设计为局限于域不变数据元素和结构,例如数量,编码文本和各种通用包含结构。这使得能够独立于特定域信息实体的定义来构建和部署稳定的数据处理软件。如前所述,通用信息模型能够实现多少“任何数据”实例,而为了实现“有意义的数据”,需要域内容模型(原型和模板)。
虽然在抽象中,原型很容易理解,模板暗示一些细微差别。模板是使已发布原型中定义的内容可用于特定用例或业务事件的工件。在健康中,这通常是“健康服务事件”,例如患者和提供者之间的特定类型的相遇。原型定义基于主题或主题的内容。血压,身体检查,报告,独立于特定的商业事件。模板提供了使用特定集合的原型,从每个集合中选择特定(经常是相当有限的)节点集合,然后以特定类型的事件特定的方式限制值和/或术语,例如“糖尿病患者入院','ED放电'等。 ICT环境中的这样的事件通常具有与它们相关联的相应的屏幕“形式”(其可以具有一个或多个“页面”或子形式以及一些工作流逻辑)因此,openEHR模板通常是应用软件的表示层中的表单的直接前导。模板是在运行时系统中使用原型的技术手段。
另一个语义成分是至关重要的:术语,与底层本体的含义。 RM / Archetypes / Templates'模型栈'定义创建和使用的信息 - 一个认识论视图,但不试图描述每个信息元素的本体语义。后者是本体的业务,例如可以在开放生物医学本体论(OBO)Foundry中找到的术语,以及诸如SNOMED CT的术语,其定义在本体论框架上命名以在特定上下文中使用。
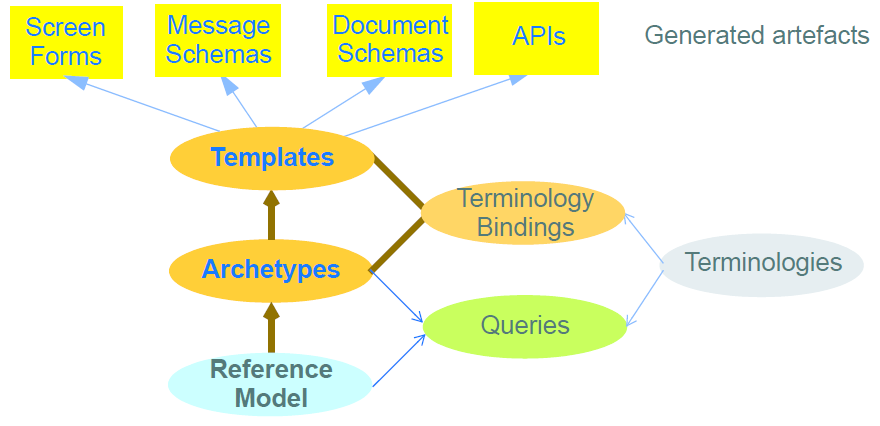
信息模型栈与术语的连接是通过术语绑定在原型和模板中进行的。通过这些,可以在原型和模板中声明元素的“名称”(本体上:元素是什么)与术语和本体实体之间的关系,以及元素值和值之间的关系域名。
语义组合中需要最终成分:查询。在原型方法下,信息查询仅根据原型元素(通过路径),术语概念和逻辑参考模型类型来定义,而不考虑持久层中使用的数据模式。基于原型的查询因此是便携式查询,并且只需要为给定的逻辑信息结构写入一次。
参考模型,原型和模板(具有绑定术语)一起构成了复杂的语义模型空间。但是,任何模型都需要部署才能有用。因为模板被定义为抽象的人工制品,所以它们能够实现单一来源生成具体的人工制品,例如XML模式,屏幕形式等等。该方法意味着可以使用用于“糖尿病患者遭遇”的数据集的单个定义来生成消息定义XSD和屏幕形式。
它是模板“操作”形式,为工具生成可用的下游混凝土制品提供了基础,其以具有典型专长和技能的“普通”开发人员可用的形式体现了所涉及的模板的所有语义。
当最终部署在操作系统中时,下游伪像使得能够创建和查询数据。由基于原型的生态系统创建的人工制品使信息系统具有高质量,语义能力和可维护性,因为数据和查询都是基于模型的,并且模型以术语和本体为基础。
所有这一切的基础当然是形式主义和工具 - 原型的语言和工具。本概述描述了原型规范及其如何配合在一起,支持工具构建以及下游基于模型的软件开发。
上述语义在以下规范中定义:
上面的第一个规范描述了Archetype标识符的语义,这相当于描述了基于原型的模型空间的结构。它还描述了生命周期管理和Archetypes版本控制的各个方面。
原型定义语言(ADL)是用于原型的正式抽象语法,可用于提供原型的默认序列表达式。它是人类理解原型语义的主要文档。
AOM是原型语义的最终形式表达,并且独立于任何特定语法。 AOM规范的主要目的是指定开发人员如何构建原型工具以及使用原型的EHR组件。
AOM中定义的语义用于表达源原型和扁平原型的对象结构。因为在ADL 2中,模板只是一种原型,AOM还描述了模板的语义。两个源表单由用户通过工具创建,而两个平面表单由工具生成。在本说明书中详细描述了如何对这些形式中的每一个使用AOM的规则。
操作模板规范定义了在下游系统和工具中使用的openEHR模板的操作形式。这对工具构建器是非常有用的。
最后,原型查询语言(AQL)规范定义了一种查询语言,它假设一个参考模型和原型作为其语义库。
本文档的其余部分提供了对基于原型的模型环境的进一步高级描述,对理解形式规范至关重要。
原型是基于主题或主题的域内容模型,以参考信息模型的约束表示。由于每个原型构成与主题有关的一组数据点的封装,所以它是可管理的,有限的大小,并且具有清楚的边界。例如,openEHR参考模型类“OBSERVATION”的“Apgar结果”原型包含与新生儿的Apgar得分相关的数据点,而“血压测量”原型包含与结果和血压测量相关的数据点。原型通过模板组装以形成在计算系统中使用的结构,诸如文档定义,消息定义等。
在下文中,除非另有限定,一般术语“原型”包括模板,其在技术上仅仅是特殊类型的原型。
原型可以通过两种方式识别:具有GUID和人类可读ID(HRID)。原型HRID结构对应于由参考模型和原型的组合创建的模型空间的结构,如下面的示例所示。

蓝色段openEHR-EHR-COMPOSITION指示参考模型空间中的实体,这里是来自openEHR参考模型的包EHR中的类COMPOSITION。绿色部分'medication_order'指示被建模的域级实体 - (药物订单的记录)(即典型医生处方的一部分)。 RM类空间和语义子空间的组合定义了由原型形式主义创建的逻辑模型空间。
我们可以将此模型空间等价地理解为本体空间,其中模型用作真实数据的本体论描述。哲学上来说,这有点像是一种僵硬的手,因为数据当然是从模型本身创造的。然而,如果模型(参考模型和原型)被定义为表示来自现实世界的信息,例如医疗保健专业人员的纸张或叙事笔记和数据输入(处方,进展记录,实验室结果等),则它们可以被理解为那些原始信息实体的本体描述。当我们遵循IT中的正常过程,并使用一个正式定义的模型来创建数据时,手势就会出现。以这种方式创建的数据可以被认为是用于通知原始建模工作的原始数据的更高精度版本。
返回到原型HRID,领先的命名空间表示Custodian组织,这里是英国NHS。 HRID中的命名空间的含义是,多个代理可以发布基于openEHR组合类的'medicationorder'原型的竞争想法,并且不会有任何冲突。尽管命名空间以通常的方式被添加到原型标识符,实际上它应该被理解为域实体上的鉴别符。换句话说,标识符uk.gov.nhs :: openEHR-EHR-COMPOSITION.medicationorder.v1和no.regjeringen :: openEHR-EHR-COMPOSITION.medicationorder.v1应该被理解为英国NHS和挪威卫生部的' medicationorder',基于相同的openEHR参考模型COMPOSITION类。
这是一个实用的措施,以避免立即的混乱。从长远来看,目的是给定域的原型语义标识符位于信息伪影类型的公共国际本体中。对于临床领域,其可以如图所示示例原型伪像本体论,其中假设基本正式本体论(BFO)第2版和信息伪像本体论(IAO)上层本体将提供临床特异性的基础模型。
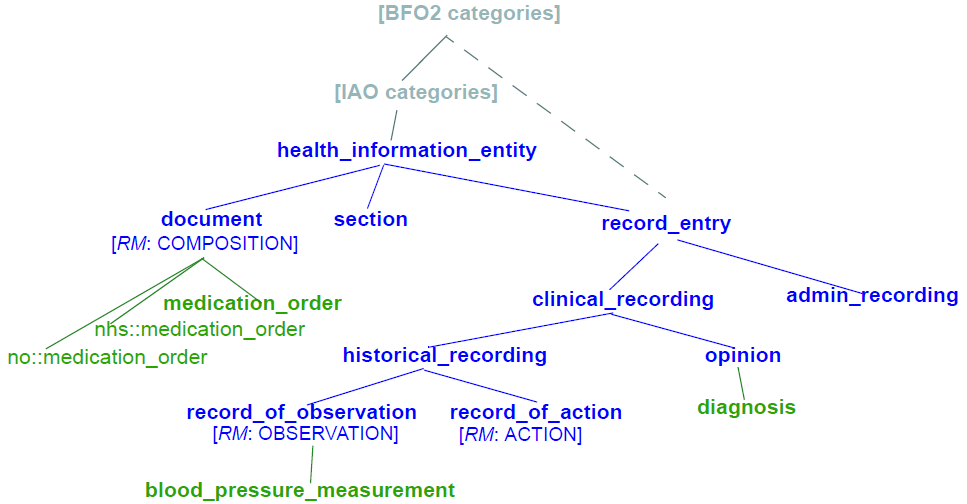
'medicationorder'的情况显示在文档/组合节点下:显示了'medicationorder'的NHS和挪威变体以及普遍接受的形式。
原型的命名空间具有重要的实际后果:不同命名空间的原型可以在同一个库工作空间内共存(见下面的定义)。这种情况可能是由于原型从原始托管人转移或分支到另一个托管人。
原型HRID可以合法地没有命名空间。这意味着它是不受控制的,不由任何组织管理。
原型标识符的最后一部分是版本。逻辑原型标识符包括主要版本,即3部分版本(例如1.5.0)的第一数字,基于主要版本号的改变在IT中通常被理解为对制造品的破坏性改变。因此,从计算的角度来看,不同的主要版本被认为是不同的伪影。完整版本还可以用于构造对物理资源有用的标识符,例如,文件或版本系统引用。
由于涉及两种类型的“保管人”或“出版者”,即参考模型保管人(通常是标准化组织),因此在整个领域(如临床信息学)的普遍本体论上取得进展可能是复杂和缓慢的,原型保管人 - 通常是主要管辖范围内的域相关组织,例如MoH信息主管部门。如果我们还假设一个组织,如开放生物和生物医学本体(OBO)的参与,一个多年的过程是明确暗示。
一个实际的观点是将一个给定的参考模型(或少数强烈相关的RM)视为固定的,并尝试开发一个原型的本体。这将需要跨原型保管人的协议,成功的结果将导致一个单一的定义空间 - 每个人都会同意,例如,“全身动脉血压测量”就是这样,并有一个短名称(比方说)'bp_measurement '。然而,这不会避免对保管人的需要,因为很清楚,对于大多数域,在地理和亚专业之间仍然存在真正的区别。例如,一个国际上认可的“妊娠记录”实体可能有真正的专业化,如“欧洲标准怀孕记录”,“瑞典怀孕记录”等,其中一些欧洲机构和瑞典卫生部都是保管人。
由于国家级原型治理组织与openEHR基金会合作,作为国际原型治理机构,在openEHR临床知识管理员主持下,在openEHR中开展了这种协调。即使这种协调水平很慢,因此不能被视为原型形式主义的目的。
因此,形式主义和工具是在最简单的现实假设的基础上设计的:参考模型类型的层次结构以及可选的命名空间原型形成一个自立的信息本体,以示例原型伪像本体中所示的相同方式,即由RM类型形成的IS-A层次结构,后面是原型。这个的实际价值有两个方面:
真实数据可以在本体中的各个点处计算分类 - 即,我们可以在计算上确定某些数据是“bpmeasurement”,“UK NHS bpmeasurement”还是仅仅是观察;
我们可以使用IS-A层次结构上的包含运算符来定义整个空间的有用子集,例如。 {any-descendant of'medical_device'},{any-descendant-or-self of OBSERVATION}等。
IS-A层次结构在原型工具(例如openEHR ADL Workbench)中可用,如图所示,它是openEHR国际原型的层次结构。
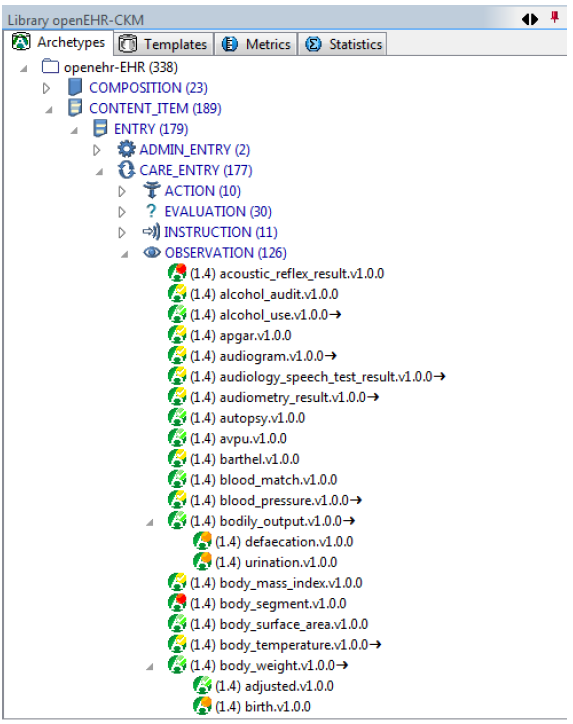
在上述虚拟原型空间中,我们可以识别不同的组或原型集合,这些原型与工具如何工作有关,特别是与标识符如何解决有关。对于可预见的未来,可以假设所有以下类型的集合都出现在特定保管人命名空间下,即原型的管理者和发布者。
原型库对应于单个工作空间或存储库中实际可用的原型的连贯集合。库中的所有原型和模板通常将基于相同的参考模型,但是不必如此,例如。在测试原型的情况下。除了后一种情况,原型库包括原型,通常设计用于在验证和创建信息时一起使用。这些可以包括非命名空间(非托管)和不同命名空间的原型,其中由于促销和/或分叉而发生混合。在后一种情况下,由库维护者来确保库中所有原型的兼容性。
一个或多个Archetype库存在于Archetype Repository中,Archetype Repository被理解为一个物理存储库,在其中管理原型,通常具有版本控制,下载功能等.Archetype Repository不意味着任何语义,而是提供一个访问单元,提交和版本控制工具。
原型库中的原型库由Custodian组织发布,对应于完全合格的原型标识符的命名空间部分。
在最外层,参考模型的原型Universe对应于该RM的所有现有原型,因此是基于该RM的所有原型库的虚拟集合。因此,它将包含由不同保管组织创建的原型,不同的RM类,各种语义实体(原型是什么,例如“血压测量”),以及所有这些的多个版本和修订版本。
在原型库内,原型之间可能存在两种关系:专业化和组合。
原型可以以类似于面向对象编程语言中的子类的方式专用于后代原型。专业原型类似于类,以相对于平面父原型的差分形式表示,即从专业化层次中的展平操作得到的有效原型。这是专业原型的可持续管理的必要先决条件。原型是另一个原型的专业化,如果它提到原型作为其父类,并且只对其定义进行更改,以使其约束比平面父类的“更窄”。注意,这可以包括对参考模型的一部分定义约束的专门原型,而不是由父原型完全约束 - 因为这仍然是“缩小”或约束。从一个专门的原型回到所有的父母,到最终的父母的原型链被称为原型谱系。对于非专业(即顶级)原型,谱系本身就是。
为了使用专门的原型,用于创作的差异形式必须通过原型谱系展平,以产生平面形式的原型,即,给定原型的独立等同物,如同它是自己构建的。扁平原型以与差分形式原型相同的串行和对象形式表示,但是除了使用差分路径之外,在语义上存在一些微小的差异。
通过使用原型创建的任何数据符合原型的平面形式,以及沿着谱系的每个原型的平面形式。
为了重用,原型可以被组成以形成语义上等同于单个大型原型的较大结构。组合允许发生两个事情:对于根据自然“级别”或信息封装来定义原型,以及通过更高级别的原型重新使用较小的原型。有两种表达组成的机制:直接引用和根据约束定义的原型槽。后者允许任何子集的原型,例如。通过包含关系定义,被表示为在组成父原型中的某一点使用的允许集合。
这些语义在ADL规范中以其语法形式详细描述,在AOM规范中以结构形式详细描述。
原型被计算地表示为原型对象模型的实例。为了持久化的目的,它需要序列化。原型定义语言(ADL)用作规范性创作和持久性语言,与编程语言语法用于表示编程结构(即,应该记住它不是语法,而是语言编译器的结构化输出)。特别地,其被设计为简洁且直观的人类可读。通常由于技术原因,提供了任何数量的其他序列。这些包括“对象转储”ODIN,XML和JSON序列化,并且可以根据新兴开发技术的技术需要包括将来的其他表示,例如OWL和OMG XMI。为了描述和描述原型形式主义,通常使用ADL。
基于XML模式的XML用于与原型有关的许多常见计算目的,并且可以在用户数量方面成为主要语法。然而,由于许多原因,XML不被用作原型的规范语法。
没有可能忍受的单个XML模式。初始发布的模式由更高效的模式替代,并且还可以由替代的XML语法替换,例如。基于XML模式的版本可以被Schematron替换或扩充。
XML作为在标准中使用的解释性语法没有什么价值,因为它自己的底层语法遮盖了原型的语义或者其使用的任何其他特定目的。上述原型的可接受XML表达式中的变化也可能在诸如此过时的文档中呈现示例。
在许多编程环境中,XML使用开始被JSON替代。
原型的XML模式可在openEHR网站上获得。
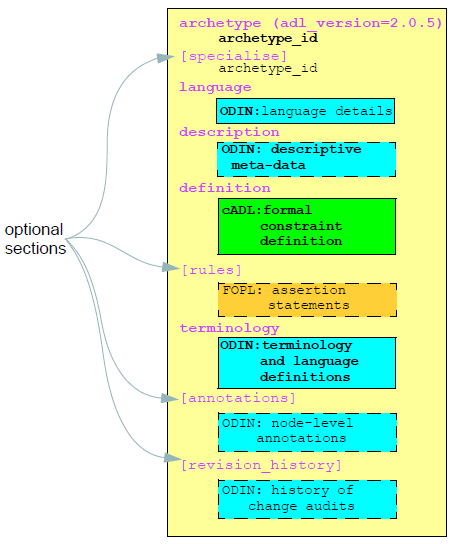
ADL使用三个子语法:cADL(ADL的约束形式),ODIN(对象数据实例符号)和一阶谓词逻辑(FOPL)的版本。 cADL和FOPL部分表达对作为基础信息模型的实例的数据的约束,其可以以UML,关系形式或以编程语言表示。 ADL本身是一个非常简单的“glue”语法,它连接从属语法的块来形成一个整体的人工制品。 cADL语法用于表示原型定义,而ODIN语法用于表示在ADL原型的语言`,描述,术语和版本历史节中出现的数据。 ADL原型的顶层结构如下图所示。
在实际系统中,原型通过使用模板被组装成更大的可用结构。模板以与专用原型相同的源形式表示,通常利用槽填充机制。它根据原型库处理以产生操作模板。后者类似于大型平面原型,是用于运行时验证的形式,也用于生成从模板派生的所有下游伪影。从语义上讲,模板执行三个功能:聚合多个原型,删除模板用例不需要的元素,缩小一些现有的约束,与专业原型相同。效果是重用原型库中需要的元素,以直接对应于用例的方式排列。
模板的此作业如下:
组成:通过指示哪个原型应该填充更高级原型的槽,将原型组成更大的结构;
元素选择:通过执行以下一个或多个操作,选择所选原型的哪些部分应保留在最终结构中:
删除:删除模板目的不需要的原型节点('数据点');
命令:标记原型节点('数据点')对于模板的运行时使用是必需的;
节点也可以是可选的,这意味着相应的数据项在运行时被认为是可选的;
狭窄约束:对原型元素或参考模型(即,尚未被模板中引用的原型约束的RM的部分)缩窄剩余约束;
set detaults:设置默认值(如果需要)。
模板可以组成任意数量的原型,但是从每个原型中选择非常少的数据点,因此具有从原始原型中定义的非常大量的数据点创建小数据集的效果。
模板中使用的原型语义在ADL规范中有详细描述;它们的使用的详细描述在ADL2规范,模板部分中给出。
AOM规范在结构形式中描述了模板的所有语义。注意,AOM不区分原型,专用原型或模板,而不是通过使用伪影类型分类器。原型和模板工作原理的所有其他差异都在工具中实现,这些工具可能会阻止或允许某些操作,具体取决于所处理的工件是原型还是模板。
原型对象模型可以被认为是内存原型或模板的模型,或者等效地,任何序列化格式的标准语法树 - 不仅仅是ADL。原型的规范抽象语法形式是ADL,但原型可以很容易地解析并序列化为XML,JSON或任何其他格式。还可以通过从原型或模板编辑工具调用合适的AOM构造API来创建内存中原型表示。这些关系,以及各形式与其规格之间的关系如下所示。
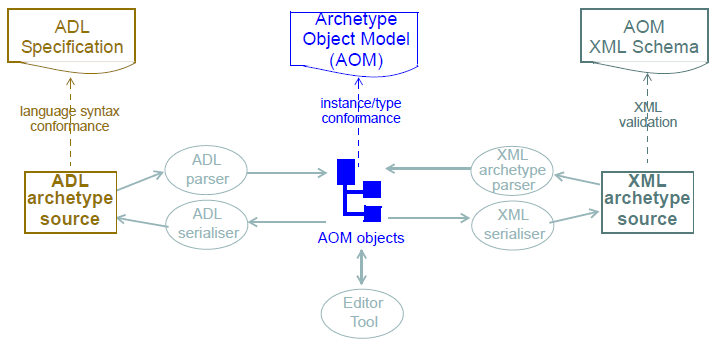
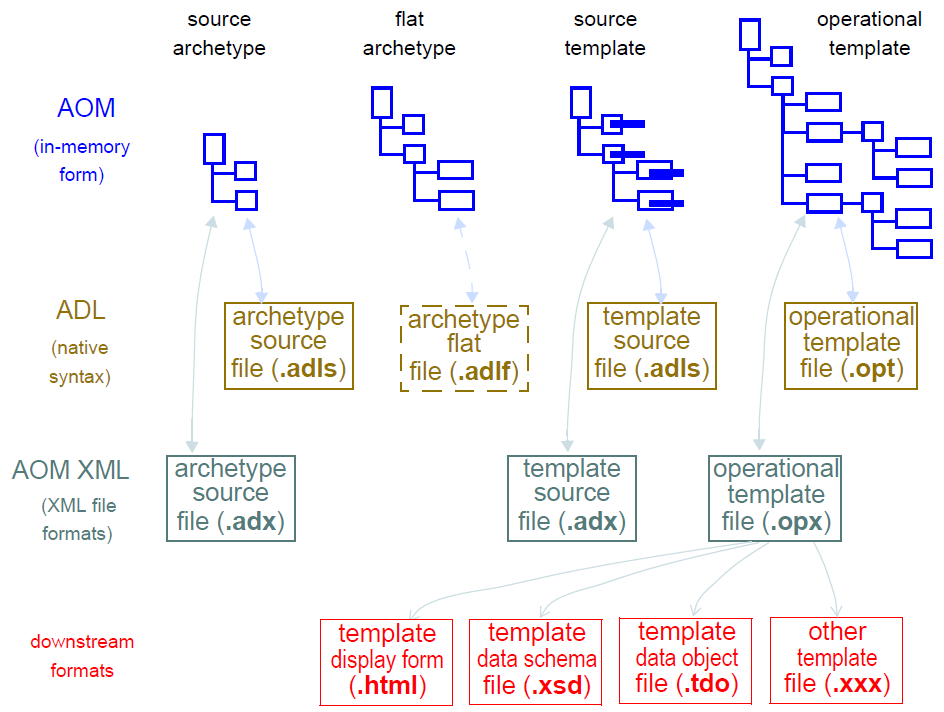
尽管任何给定的环境倾向于使用单个序列化形式,但是源和平面形式原型和模板的存在可能在多个序列化格式中可能最初看起来是混乱的。 下图说明了所有可能的原型和模板工件类型,包括文件类型。
原型是根据与面向对象编程环境中的类定义非常相似的许多步骤创作和转换的。过程中的活动如下:
创作:创建源形式的原型,用AOM对象表示;
验证:确定原型是否满足语义有效性规则;如果是专业的,则需要当前原型的平面形式;
扁平:创建扁平原型。
模板以相同的方式创作,尽管通常只使用强制,禁止和细化。最后一步是生成操作模板,它是由模板引用的源定义的完全展平和替换形式。
该过程的工具链如下所示。从软件开发的角度来看,模板创作是起点。模板引用一个或多个原型,因此其编译(解析,验证,展平)涉及模板源和引用原型的已验证扁平形式。使用这些作为输入,模板平整器可以生成最终输出,操作模板。
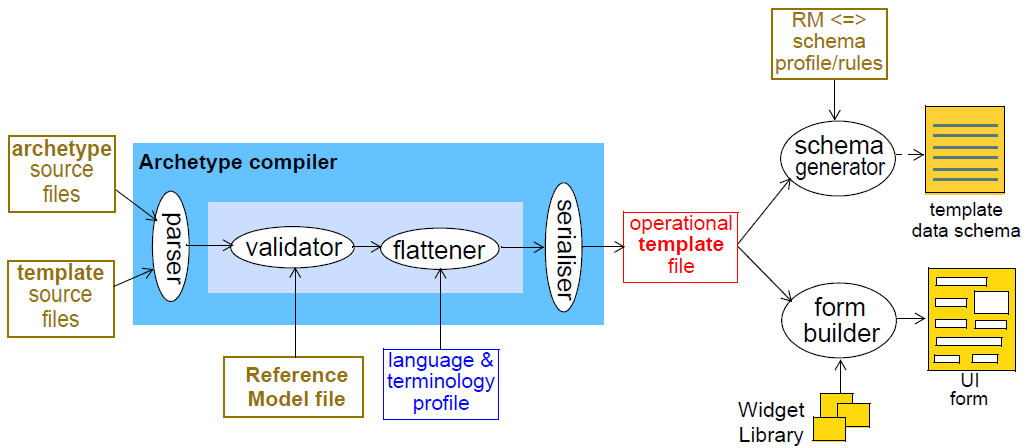
一个解析,验证,平面化和从一个文件库生成新输出的工具称为编译器。由于专业化的存在,原型专业化谱系而不仅仅是单个原型被处理 - 即专门的原型只能与其专业化父类一起编译到最高级别。每个这样的原型还可能具有供应商原型的列表,即通过ADL use_reference语句引用的原型。为了编译原型,它的所有供应商和专业化父母必须已经编译。
这正是面向对象编程环境的工作原理。对于任何给定的谱系,编译从顶层原型向下进行。每个原型都被验证,如果通过,则与链中的父级拼接。这继续,直到到达原始编译的原型。在原型没有专业化的情况下,编译涉及一个原型和它的供应商。
下图说明了编译过程创建的原型沿袭的对象结构,其中元素对应于顶级原型的粗体。差分输入文件由解析器转换为差分对象解析树,显示在“flattener”进程的左侧。相同的结构将由编辑器应用程序创建。
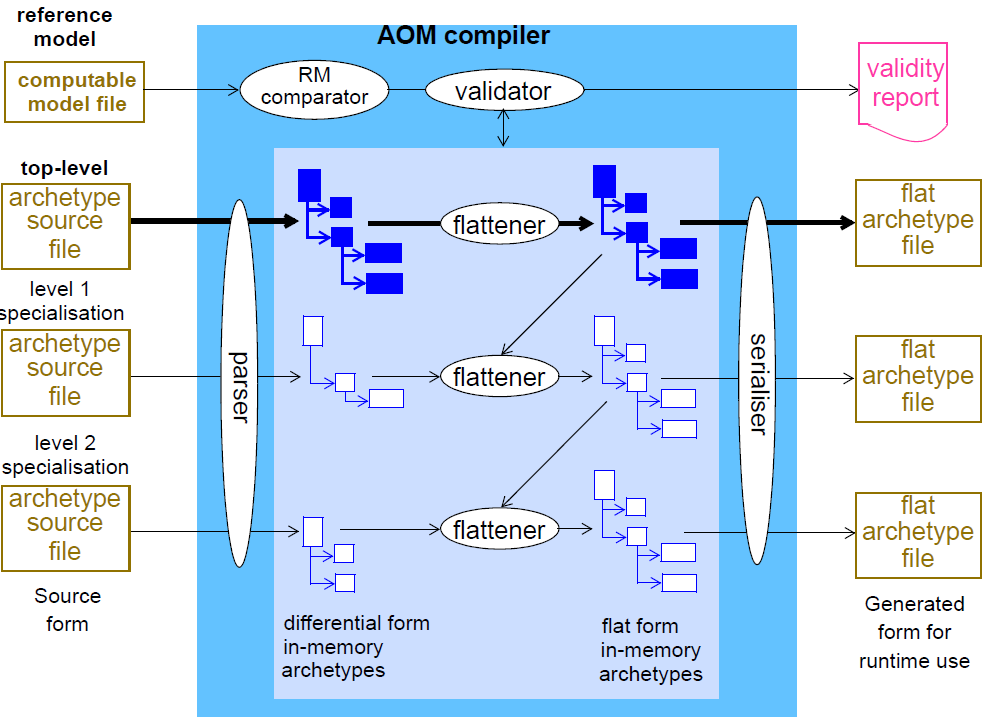
内存中差异表示由语义检查器验证,其验证许多事情,例如在定义部分中引用的术语代码在术语部分中定义。它还可以根据相关参考模型的规范验证原型中提及的类和属性。
编译过程的结果可以在openEHR ADL Workbench中的原型可视化中看到。
在创作(即“设计时”)环境中,人工制品应始终被视为“可疑”,除非通过可靠的验证证明。这是真的,不管原始的语法 - ADL,XML或其他东西。然而,一旦验证,平面形式可以以适合于编辑器工具使用的格式(ADL,XML,...)以及也可以被认为是内存结构的可靠纯对象序列化的格式。后一种形式通常是基于XML的,但可以是任何对象表示形式,例如JSON,openEHR ODIN(以前的dADL)语法,YAML,二进制形式或数据库结构。它不会是抽象语法形式,如ADL,因为在抽象语法和对象形式之间需要一个不可避免的语义变换。
这个纯对象序列化的效用是它可以用作被验证的假象的持久性,仅使用非验证流解析器而不是多遍验证编译器转换为内存形式。这允许这样的经验证的伪像在设计环境中使用,并且更重要地,在没有编译错误的危险的运行时系统中使用。它是用于从Java源代码创建.jar文件以及从C#源代码创建.Net程序集的相同原则。
在openEHR环境中,使用包括数字签名的各种机制来实现原型的创作和持久化形式的管理,这些机制在openEHR
最后更新2016-02-06 18:04:09 GMT